Failover Planning Guide and checklist
- Introduction to this Guide
- Chapter 2 - Checklist to plan for Failover
- Planning Check List Excel Download
Introduction to this Guide
Overview
The Eyeglass PowerScale edition greatly simplifies DR with DFS. The solution allows DFS to maintain targets (UNC paths) that point at both source and destination clusters.
The failover and failback operations are initiated from Eyeglass and move configuration data to the writeable copy of the UNC target. Grouping of shares by SyncIQ policy allows Eyeglass to automatically protect shares added to the PowerScale. Quotas are also detected and protected automatically.
The following checklist will assist you in plan and test your configuration for Failover in the event DR (Disaster Recovery) is needed.
Chapter 2 - Checklist to plan for Failover
Steps Before failover Day | Task | Description | Completed |
0 | Document DR Runbook plan |
| |
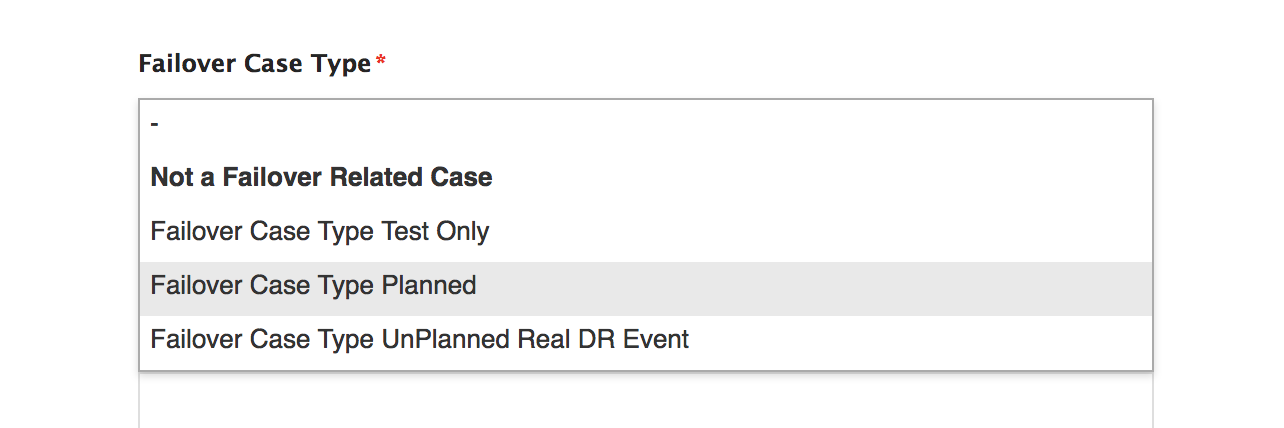
0A | Submit support logs for failover readiness audit (7 days before planned event) (see image for case option to request assessment) | ||
0B | Take failover training labs to practice execution | ||
1A | Review DR Design Best Practices Review Failover Release notes Warning: Mandatory Step for all customers DR Assistance requires acceptance before continuing | ||
1B | Upgrade Eyeglass to latest version (Eyeglass releases includes failover rules engine updates that add rules found from other customer failovers that continuously improve or avoid known failover issues) Failover Release Notes | ||
1C | Test DR procedures |
| |
1D | Benchmark Failover (access Zone) |
| |
1E | Benchmark Failover (DFS Mode) |
| |
2 | Contact list for failover day |
| |
3 | Reduce failover and failback time - Run manual domain mark jobs on all syncIQ policy paths (this will speed up failover because domain mark can take a long time to complete and elongates the failover time) | All policies run this procedure on all policies. Domain mark | |
4 | Count shares,exports, NFS alias, quotas on source and target with OneFS UI | Validates approximate config count is synced correctly (also verify Superna Eyeglass DR Dashboard) (there should be no quotas synced on target - only shares, exports and NFS alias) | |
5 | Verify dual delegation in DNS before failover | This verifies that DNS is pre-configured for failover for all Smartconnect Zones that will be failed over (Access Zone failover fails over all Smartconnect Zones on all IP pools in the Access Zone) | |
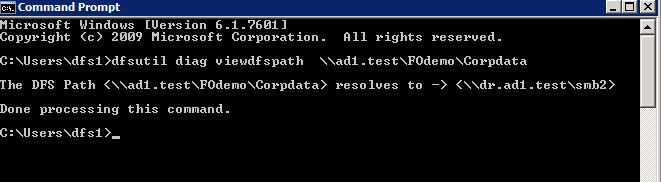
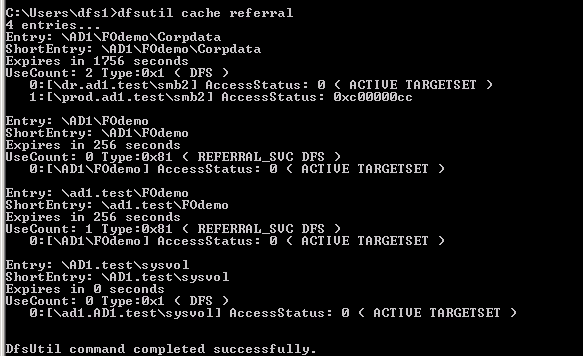
6 | DFS failover preparation |
dfsutil tool downloaded by OS type check path resolution
| |
7 | Communicate to application teams and business units that use the cluster the failover outage impact |
| |
| 8 | Set all policies schedule to every 15 minutes or less 1 day prior to the failover to ensure data is staying in sync. This also ensures the failover speed will be optimized | This step is critical step to changne to avoid long running policies or long running jobs that will extend your failover and maintenance window. Specifically ensure run on change is never left enabled since policies that are running cannot be controled for failover. | |
Steps on the failover Day | Task | Description | Completed |
0 | SMB and NFS IO paused or stopped before failover start to avoid data loss | For SMB protocol the 2.0 or later feature can be used to block IO to shares with DR assistant. This inserts a deny read permission dynamically before failover starts and removes after failover completes. 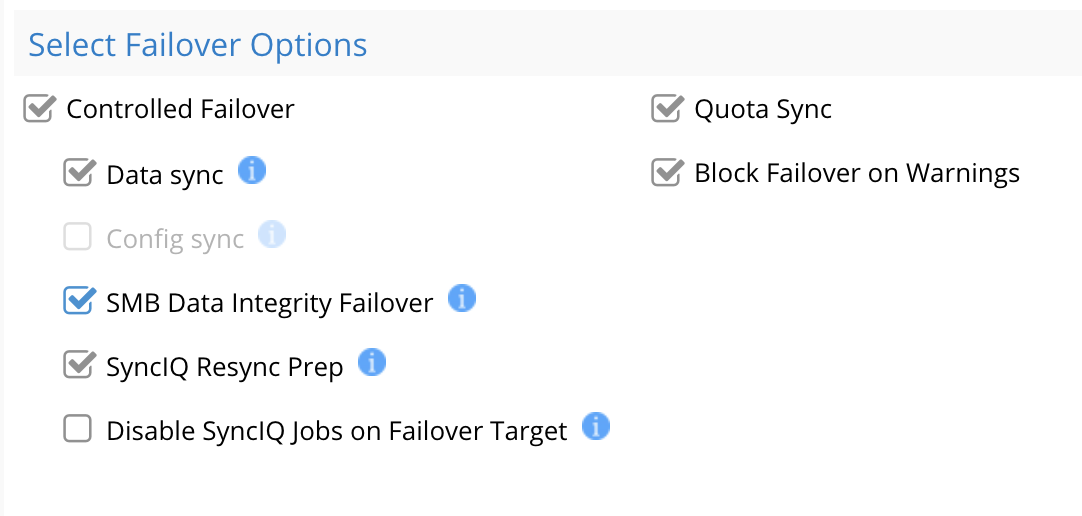 NFS requires the protocol to be disable to guarantee no IO. Exports should be unmounted before disabling the the protocol on the cluster. | |
1 | Force run syncIQ policies 1 hour before planned failover | Run each syncIQ policy before so that the failover policy run will less data to sync | |
2 | Execute failover | ||
3 | Monitor failover | How to Monitor the Eyeglass Assisted Failover | |
4 | If Required Data recovery guide | ||
5 | Ensure Active Directory admin is available | ADSIedit recovery steps are required and needs Active Directory Administrator access to cluster machine accounts | |
After Failover | Test Data Access | Use post failover steps guided steps |