Eyeglass and PowerScale Failover Best Practices
- IMPORTANT READ this --- All Planned Failover Attempts MUST read this support statement
- IMPORTANT READ this --- Do not attempt failover without completing this step. Best Practise for Fast Failback and Pre Failover Steps
- IMPORTANT READ this --- Failover timeouts with Eyeglass - Cluster Operations that can take longer than planned
- Best Practice General:
- SyncIQ Performance Tuning Best Practices
- Data Loss Considerations
- Best practices for DFS mode Failover Design:
- Best practices for Access Zone and per SyncIQ mode Failover Design
- Best Practise DNS Configuration for Access Zone Failover
- Best Practice for Protecting Data for HA and Failover with Eyeglass
- Best Practice for PowerScale Networking
- Best Practice for Kerberos Service Principal Names (SPN’s)
- Best practice to verify the following on all DNS
- Best practice DNS delegation of NS records
- Best practice - Do DR Testing with RunBook Robot for Access Zones
This section is a collection of best practices. Details on configuration is in the admin guide. This is section is aimed at quick short descriptions of best practices in one easy to read place, that covers Eyeglass and SyncIQ.
IMPORTANT READ this --- All Planned Failover Attempts MUST read this support statement
- Planned failovers must use the latest software available. Each release has fixes, improvements and new error conditions blocked or warned that can prevent issues or robuts failover.
- Always plan to upgrade appliance software as step before any planned failover.
- This is a supportability requirement for customers and expected as basic step in keeping DR software updated as key component for planning and readiness.
- This requirement supersedes any change management or IT policies that require upgrades to be planned, this must be factored into any planned failover. Trial keys are available for lab systems as are PowerScale Simulators for testing upgrades in advance of a planned failover event.
- EULA requires customers to maintain current updated software as condition of the license when raising failover support cases.
IMPORTANT READ this --- Do not attempt failover without completing this step. Best Practise for Fast Failback and Pre Failover Steps
- Run domain mark manually on all SyncIQ paths following instructions in online PowerScale documentation. Read this to understand why its important to run it now (see section Prepare policy for accelerated failback performance)
Create a SyncIQ domain
- You can create a SyncIQ domain to increase the speed at which failback is performed for a replication policy.
- Failing back a replication policy requires that a SyncIQ domain be created for the source directory. OneFS automatically creates a SyncIQ domain during the failback process. However, if you intend on failing back a replication policy, it is recommended that you create a SyncIQ domain for the source directory of the replication policy while the directory is empty.
Create a protection domain Procedures
You can create replication or snapshot revert domains to facilitate snapshot revert and failover operations. You cannot create a SmartLock domain. OneFS automatically creates a SmartLock domain when you create a SmartLock directory.
- Click Cluster Management > Job Operations > Job Types
- In the Job Types area, in the DomainMark row, from the Actions column, select Start Job.
- In the Domain Root Path field, type the path of the directory you want to create a protection domain for.
- From the Type of domain list, specify the type of domain you want to create.
- Ensure that the Delete this domain check box is cleared.
- Click Start Job.
- Confirm completed step
- Run this on source cluster isi_classic domain list
- Output should show SyncIQ domain on each syncIQ policy that has been created if you have successfully run domain mark on all policies
- If any paths are missing repeat step 4
IMPORTANT READ this --- Failover timeouts with Eyeglass - Cluster Operations that can take longer than planned
The following section is very important to review, If you have never failed over a policy than you have never run domain mark which eyeglass and PowerScale require to run domain mark job on the source cluster before failover. The following conditions WILL increase the time to run cluster operations and if you have policies that match this criteria then increase the timeout for Eyeglass failover jobs.
Policies criteria for increased timeout:
- Many TB of data protected by Single SyncIQ policy (many is not precise but if you think it's a lot of data for your environment then this applies to you)
- Many small files (same as above if you know it has a lot then it likely does and this applies to you)
- You have daily schedules for SyncIQ AND you have high change rate in GB’s per day and policies take over 1 hour to run normally each day
If you have policies as per above AND you have run domain mark in advance of a failover as recommended above as a MUST DO. Domain mark can take hours so read and please do this before failover.
When Eyeglass starts and cluster task (example start resync prep, run policy, even make writeable for policies that match the criteria above). Then the per task time should be increased. From the default of 180 minutes to a number greater than 180 minutes based on looking RPO graph or report of the policy you are planning to failover. Do this before attempting a failover or failback of a policy that matches the above criteria
How to change the timeout
igls adv failovertimeout set --minutes 360
Best Practice General:
- Eyeglass - We recommend DFS mode for SMB share protection and DR
- Eyeglass - We recommend Access Zone Failover when NFS and SMB data needs to failover together
- Eyeglass - We recommend syncIQ policy mode failover for customers with small numbers of NFS exports and hosts for automation
- Eyeglass We recommend Access zone when multi protocol SMB/NFS is required within a single Access zone OR when only NFS DR protection is required
- Eyeglass NFS only failover - Use simpler per policy Failover with Eyeglass and unmount remount new DR Smartconnect zone name. It’s faster and requires less planning and configuration than Access Zone Failover
- Eyeglass Multi-protocol failover allows both protocols to failover together using Access Zone failover
- PowerScale - For a syncIQ best practise for System level recovery you can refer to EMC document (PowerScale - Backup and recovery guide) https://www.emc.com/collateral/TechnicalDocument/docu56055_onefs-backup-recovery-guide-7-2.pdf
- Eyeglass - Create smartconnect mapping alias hints on all ip subnet pools, hint the syncIQ smartconnect zone with ignore to ensure it's not failed over
- Eyeglass - Delegate machine account credentials to cluster machine accounts in Active Directory
- Eyeglass - Enable phone home support for faster support response times
- Eyeglass - Configure Run Book Robot Access Zone and policies to ensure failover and failback is functioning daily
- PowerScale - Always use FQDN on Smartconnect zone names
- PowerScale - Create a SyncIQ Failback Domain to ensure fail back operations take less time
- Create a SyncIQ domain You can create a SyncIQ domain to increase the speed at which failback is performed for a replication policy. Because you can fail back only synchronization policies, it is not necessary to create SyncIQ domains for copy policies.
- Failing back a replication policy requires that a SyncIQ domain be created for the source directory. OneFS automatically creates a SyncIQ domain during the failback process. However, if you intend on failing back a replication policy, it is recommended that you create a SyncIQ domain for the source directory of the replication policy while the directory is empty. Creating a domain for a directory that contains less data takes less time.
- Procedure 1. Click Cluster Management > Job Operations > Job Types. 2. In the Job Types area, in the DomainMark row, from the Actions column, select Start Job. 3. In the Domain Root Path field, type the path of a source directory of a replication policy. 4. From the Type of domain list, select SyncIQ. 5. Ensure that the Delete domain check box is cleared. 6. Click Start Job.
- PowerScale - Create an IP and smartconnect pool that is only used for SyncIQ and create policies with run policy only on nodes subnet IP Pool/Smartconnect zone.
- Select option to Connect to nodes in the target smartconnect zone when creating policies
- PowerScale - Don't mount data using the SyncIQ smartconnect zone, use other IP pools and smartconnect zones for users to mount data
This section covers key topics to review before planning DR with Eyeglass
SyncIQ Performance Tuning Best Practices
Consult the document below to turn SyncIQ job worker threads per node for high latency WAN and faster SyncIQ node operations (Syncing, make writeable, resync prep steps).
OneFS 7 and 8 are both covered in the document below.
https://www.emc.com/collateral/hardware/white-papers/h8224-replication-PowerScale-synciq-wp.pdf
Data Loss Considerations
When SyncIQ is set to a schedule or on changes mode it’s important to understand the impact to data loss on failover operations.
- When a SyncIQ job is running and Eyeglass failover job is started the default behaviour will attempt to start a final data sync by running the SyncIQ policies in the job.
- If there is an existing SyncIQ Job running, Eyeglass failover will wait a maximum of 1 hour for the running SyncIQ Policy job to complete.
- For Urgent Failover requirements skip config sync and data sync option in the DR assistant UI by unselecting.
- If SyncIQ Job has not completed with an hour, an error is returned and the failover is aborted.
- Data Loss impact - Since SyncIQ is snapshot based, changes that have occurred since the start of the existing running job will be lost. Depending on the start time of the currently running job, this could represent a large amount of data
- Mitigate Data Loss - Login to PowerScale to verify whether a SyncIQ Job is running for the policies being failed over.
- Steps: Wait for the running job to complete and then start the failover. You may also consider disconnecting client access at this point to ensure that there is not a large amount of data that requires replication during SyncIQ Job run by the failover.
- Set the SyncIQ Job schedule to manual before starting a failover. Eyeglass will run the SyncIQ policy as part of the failover procedure.
Best practices for DFS mode Failover Design:
- DO Use Domain based DFS roots
- DO Use DFS referral ordered list to select production UNC path as default first in the list to speed up referral processing and mount times
- DO Use UNC path targets that point to SmartConnect zones
- DO Name SmartConnect zones differently on source and target clusters so that debugging with dfsutil.exe is easier and smartconnect can load the cluster nodes during normal operations and after with failover
- DO Group one or more SyncIQ policies by name and enable DFS mode in Eyeglass to failover related SyncIQ policies with DFS. (No hard rule requires this but it's easier to manage groups of related DFS failover if the names have similar prefix)
- DO Create dedicated IP pools on source and target clusters for DFS protected data
- Within an Access Zone, create igls-ignore hints to ensure smartconnect zones are not failed over with Access Zone failover
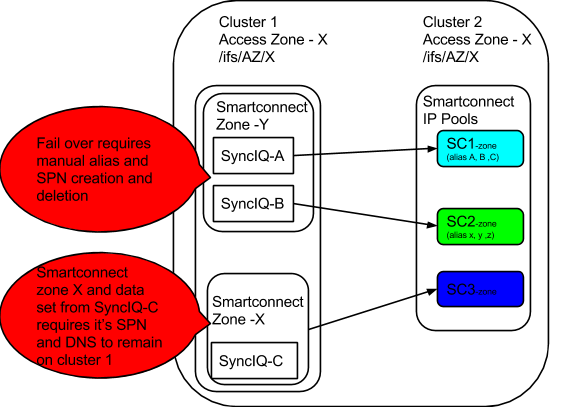
Best practices for Access Zone and per SyncIQ mode Failover Design
Sub access Zone means a syncIQ policy within an access zone is used for failover of the data protected by the policy. This is supported but has limitations in amount of automation possible with this option.
- Don’t attempt Failover of a single SyncIQ policy within an Access zone unless you are prepared for manual steps below.
- There is no method to map a SyncIQ policy to a SmartConnect zone used by clients to mount the data. Incorrect configuration, or failing over a SmartConnect zone using an alias could impact other clients using the SmartConnect zone. Eyeglass can not failover SmartConnect zones without risk of causing inaccessible data on the production cluster unless ALL Smartconnect Zones are failed over to the target cluster.
- The storage admin is responsible to failover the SmartConnect zone manually in this scenario
- The SPN delete of the access zone and creation on the target cluster is also a manual step the storage admin must execute using ISI commands.
- Do configure Access zone failover and design DR to failover all policies and SmartConnect zones in the access zone
- Do all SyncIQ policies to be at the same level as the Access Zone base path or lower in the file system
- Do create shares or exports underneath the path of SyncIQ policies to ensure they are automatically protected as well.
- Do setup subnet:pool mappings for Access Zone failover using hints to map pools
- Do setup Runbook Robot Advanced with Access zone configuration and verify it succeeds before attempting an Access zone failover
- Do Use DFS mode for SMB within an Access Zone Failover Multi Protocol design
- Don’t Failover with Eyeglass per SyncIQ level failover unless you understand the limitations below.
- To allow partial, single SyncIQ policy(s) within an Access Zone the following constraints apply:
- Any smartconnect zones used are assumed to be manually failed over with aliases and DNS updates to point DNS at target cluster smartconnect ip address
- AD SPN creation on target and deletion on source cluster is manual, since Eyeglass does not know which smartconnect zones and SPN’s are required on the source cluster after a policy is failed over leaving data accessible on the source cluster
Best Practise DNS Configuration for Access Zone Failover
- DNS that delegates NS records to Smartconnect Zones are the last step in the failover process to point the the failover Smartconnect Service IP on the target cluster (typically at the DR site).
- This NS record is setup to point at the SSIP of the production cluster for the Smartconnect Zones within the Access Zone that will be failed over.
- SmartConnect Zone aliases will also have NS records to delegate the alias entries as well to the SmartConnect Zone SSIP that has the alias assigned.
- Delegation should use an A record for each SSIP but the Delegation for the NS should use a CNAME that points to the A record. This is best practice and simplifies the update on failover of the CNAME to point at the DR cluster SSIP A record
Best Practice for Protecting Data for HA and Failover with Eyeglass
- DO - Organize Data into Protocol failover policies example policies for SMB and policies for NFS to take advantage of DFS mode
- DO - Organize Data / SyncIQ Policies / Shares / Exports / Aliases / Quotas by Zone for failover
- DO - Shares/Exports/Alias should be grouped into Zones based on which data sets that need to be failed over together.
- DO - Map each subnet/pool clients use to access data to a target cluster subnet\pool using Eyeglass hint aliases
- DON’T - Put SyncIQ policies at a level above the Access Zone root directory
- DON’T - Use excludes and includes in your SyncIQ Policy. Excluded directory will be read-only after failover. For DFS mode, share on source cluster related to excluded path is not preserved
Best Practice for PowerScale Networking
- It’s best to use fewer ip pools to simplify DNS, Alias creation on failover and reduce updates to DNS required for failover.
- Example:
- SmartConnect Zone for Data
- SmartConnect Zone for SyncIQ
- SmartConnect Zone for management (Eyeglass and other applications)
- SmartConnect Zone for Backup
Best Practice for Kerberos Service Principal Names (SPN’s)
- Use Eyeglass DFS mode to limit kerberos authentication issues for cluster machine accounts
- If NTLM fallback is disabled OR Microsoft patches or new OS’s disable NTLM fallback, you don’t want your DR strategy depending on authentication fallback to a legacy protocol. It’s best to ensure SPN’s are accurate for Kerberos authentication and use Access Zone failover as the unit of failover.
Best practice to verify the following on all DNS
To prevent giving out stale DNS entries, the DNS time-to-live (TTL) on the NS delegations should be set to zero, or as close to zero as possible, so that the DNS information is as fresh as possible.
Certain clients perform DNS caching and might not connect to the node with the lowest load if they make multiple connections within the lifetime of the cached address.
Do not create reverse DNS entries, also known as pointer (PTR) records, for PowerScale SmartConnect service IP addresses or SmartConnect zone names. SmartConnect does not provide reverse lookups. OR see #4 below as alternative.
DO If A Records are used for PowerScale node IP's and SSIP's. Make sure forward and reverse lookups match example nslookup ip x returns host name Y and nslookup of y returns IP X. This is required to ensure TLS connections function correctly, since TLS will validate ip to name and name to ip address to protect against man in the middle attacks to TLS connections.
Best practice DNS delegation of NS records
This section describes best practices for DNS delegation for PowerScale clusters.
- Delegate to address (A) records, not to IP addresses. The SmartConnect service IP on an PowerScale cluster must be created in DNS as an address (A) record, also called a host entry. An A record maps a URL such as www.superna.net to its corresponding IP address. Delegating to an A record means that if you ever need to failover the entire cluster, you can do so by changing just one DNS A record. All other nameserver delegations can be left alone. In many enterprises, it is easier to have an A record updated than to update a name server record, because of the perceived complexity of the process.
- Use one name server record for each SmartConnect zone name or alias. We recommend creating one delegation for each SmartConnect zone name or for each SmartConnect zone alias on a cluster. This method permits failover of only a portion of the cluster's workflow—one SmartConnect zone—without affecting any other zones. This method is useful for scenarios such as testing disaster recovery failover and moving workflows between data centers.
- Follow consistent mount paths
- Mount entries for any NFS connections must have a consistent mount point, in the format of sczonename.domain.com:/ifs/path. This way, when you fail over, you don't have to manually edit your fstab or automount entries.
- Use Access Zones to compartmentalize your data based on importance. If your environment is OneFS 7.1.1 or later and you use access zones, you must define an access zone root path to help segment data into the appropriate access zone and enable the data to be compartmentalized. This is similar to what Celerra or VNX administrators might do if they have a VDM that has its own root file system. So, in addition to the default System access zone, you must add another layer. For example: /ifs/clustername/accesszonename/
- Recommend to your client system administrators that they turn off client DNS caching, where possible. To handle client requests properly, SmartConnect requires that clients use the latest DNS entries. If clients cache SmartConnect DNS information, they might connect to incorrect SmartConnect zone names. In this situation, SmartConnect might not appear to be functioning properly.
- Do NOT: We do not recommend creating a single delegation for each cluster and then creating the SmartConnect zones as sub records of that delegation
SmartConnect service IPs Each cluster needs only one SmartConnect service IP (SSIP), as long as there are no firewalls between the infrastructure DNS servers, and the SSIP that block TCP and UDP port 53. It doesn’t matter how many domains or subnets the cluster is joined to or participates in. SmartConnect is essentially a very selective DNS server that answers only for the SmartConnect zone names and SmartConnect zone aliases that are configured on it. A DNS server doesn’t have to respond with an IP address from the subnet that the DNS server is in: it responds only with the correct IP address based on the name being looked up. Which subnet the DNS server resides in is irrelevant.
This above means that failover to the target cluster can update the A record to point to the SSIP of the target cluster using the hints mapping described below for Eyeglass to create aliases in the correct smartconnect subnet on the target.
Best practice - Do DR Testing with RunBook Robot for Access Zones
Note: Runbook Robot is Access Zone Failover and allows testing of Access Zone failover on non-production access zones
- It is best practice to setup an environment with non-production data and shares / exports / quotas representative of the production environment and run Failover and Failback testing to understand the failover operation in your environment with Eyeglass DR Assistant.
- It is best practice to set up SyncIQ Robot for regular automated Failover and Failback for non-production data and shares / exports / quotas in your environment.