S3 Storage Bucket Configurations Options , Operations and Settings
- Overview
- How to Cancel a Running Archive Job
- How to Configure S3 Storage bucket retention, versioning to meet your File copy Archive Use case
- Use Case: Data Retention with Scheduled Copies with or without bucket Versioning
- Use Case: One Time Copy Data Archiving
- How to clean up orphaned multi part file uploads
- Amazon S3 Procedure
- How to Configure Amazon AWS Glacier
- How to apply single File storage class change for testing Glacier
- How To recall a file from Glacier:
- How to configure Glacier Lifecycle policies on a storage bucket
- How to Configure Storage Tier Lifecycle Policies with Azure Blob Storage
- How to Monitor target storage versus your backed up source file system paths
- Supported S3 storage classes
Overview
This section covers storage bucket optional configurations and operational procedures.
How to Cancel a Running Archive Job
- First get a list of running jobs.
- searchctl jobs running (this command will return job id's).
- searchctl jobs cancel --id job-xxxxxxxx (enter the job id you want to cancel. NOTE: this will stop copying files, but files that are already copied will be left in the S3 storage up to the time the copy was canceled).
How to Configure S3 Storage bucket retention, versioning to meet your File copy Archive Use case
Use Case: Data Retention with Scheduled Copies with or without bucket Versioning
- This copy mode will run on a schedule to copy all folders configured without --manual flag setting.
- The full SmartCopy will check if the target S3 file exists and skip existing files that are the same version.
- Files that are modified AND a previous version exists in the S3 storage will be updated in the S3 storage.
- Object Retention:
- Best practice is to set the S3 retention policy at the bucket level so that all new objects automatically get retention set per object. Use different storage buckets with different retention policies or use versioning feature on the S3 storage target to set retention per version of the file. See vendor documentation on how to configure retention policies.
- (Optional) Enable Bucket versioning to keep previous versions with an expiry set for each version in days. This will will allow modified files to be uploaded while preserving the old version of the file should it need to be restored.
- Example: For Amazon S3 enables each version of a file uploaded with 45 day expiry.
- NOTE: If a file changes several times between Full Copy jobs only the last version modified prior to the copy job will be stored.
Use Case: One Time Copy Data Archiving
- To clean up data and copy to S3 storage for long term archive and legal retention. This use case is a 2 step process.
- Create a folder target configuration but add the --manual flag which excludes the folder from scheduled copies.
- Run the archive job (see guide here on running archive jobs).
- The copy job will run and review the copy results for success and failures. See guide here.
- Once you have verified all all the data is copied with an S3 browser tool (i.e. Cyberduck, or S3 Browser), run the PowerScale Tree Delete command to submit a job to delete the data that was copied. Consult Dell Documentation on Tree Delete command.
- Recommendation: Create a storage bucket for long term archive and set the Time to Live on the storage bucket to met your data retention requirements. Consult the S3 target device documentation on how to configure the TTL.
- Copy to new target path:
- The run archive job has a flag to add a prefix with --prefix xxx where xxx is the prefix to add to the S3 path (see guide here) to the S3 storage bucket path which is useful to copy the data to a 2nd path in the S3 storage and not overwrite the existing path. This allows creating multiple folders of the same source path in the target S3 storage. This can be used for present the S3 data over file sharing protocols (i.e. ECS feature or direct access to the S3 data for application use).
- NOTE: You can run a copy job multiple times using the CLI if data has changed on the source path and a full smart copy job will run again.
How to clean up orphaned multi part file uploads
Multi part upload can fail for various reasons and leaves orphaned incomplete files in the storage bucket that should be cleaned up since they are not a complete file. See the procedures below for each S3 provider. NOTE: Golden Copy will issue an Abort Multi Part API command to instruct the target to delete partial uploads. The procedures below should still be enabled in case the S3 target does not complete the clean up or does not support the Abort Multi Part API command.
Amazon S3 Procedure
- Login to Amazon S3 console.
- Click on the storage bucket name.
- Click on Management tab.
-
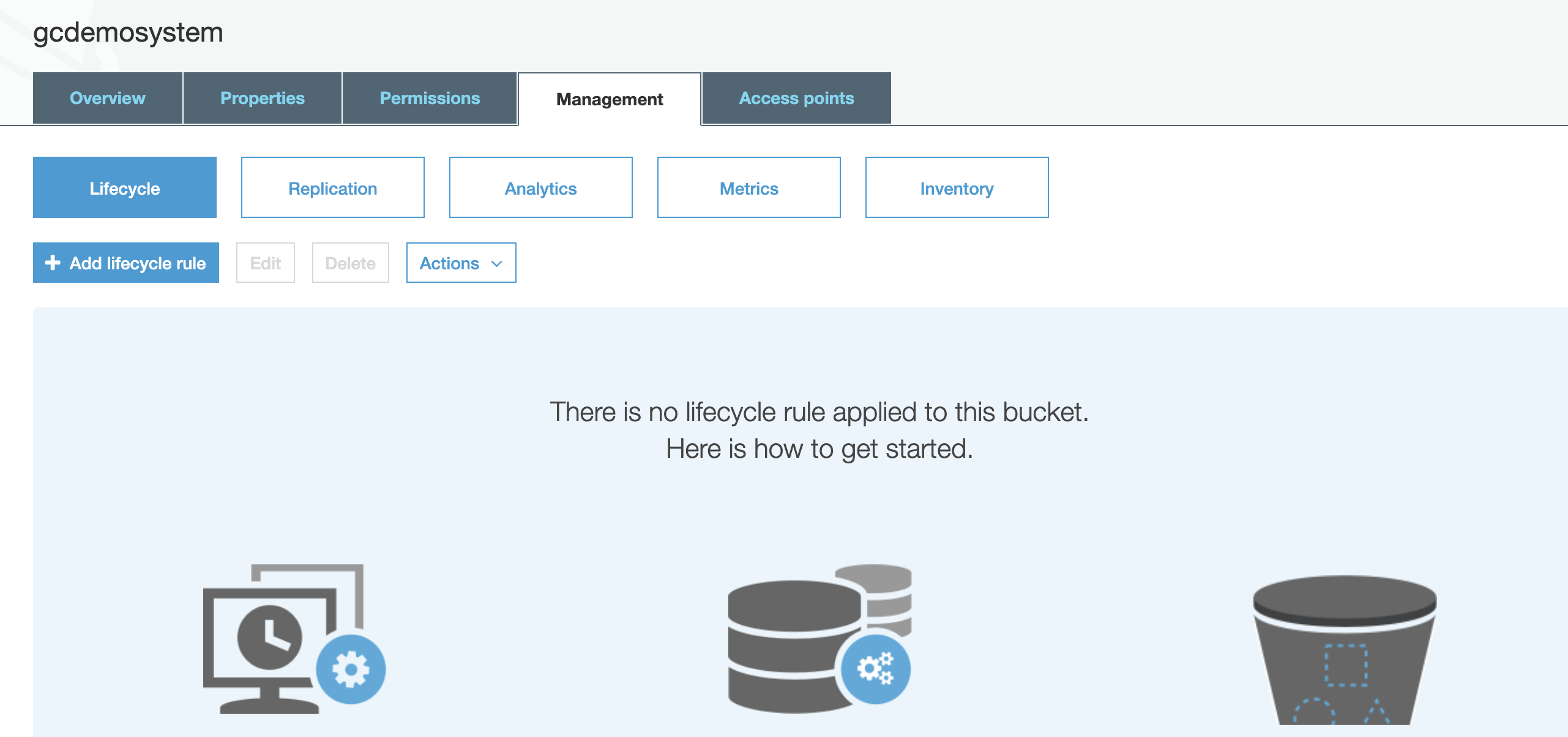
- Click Add life cycle rule.
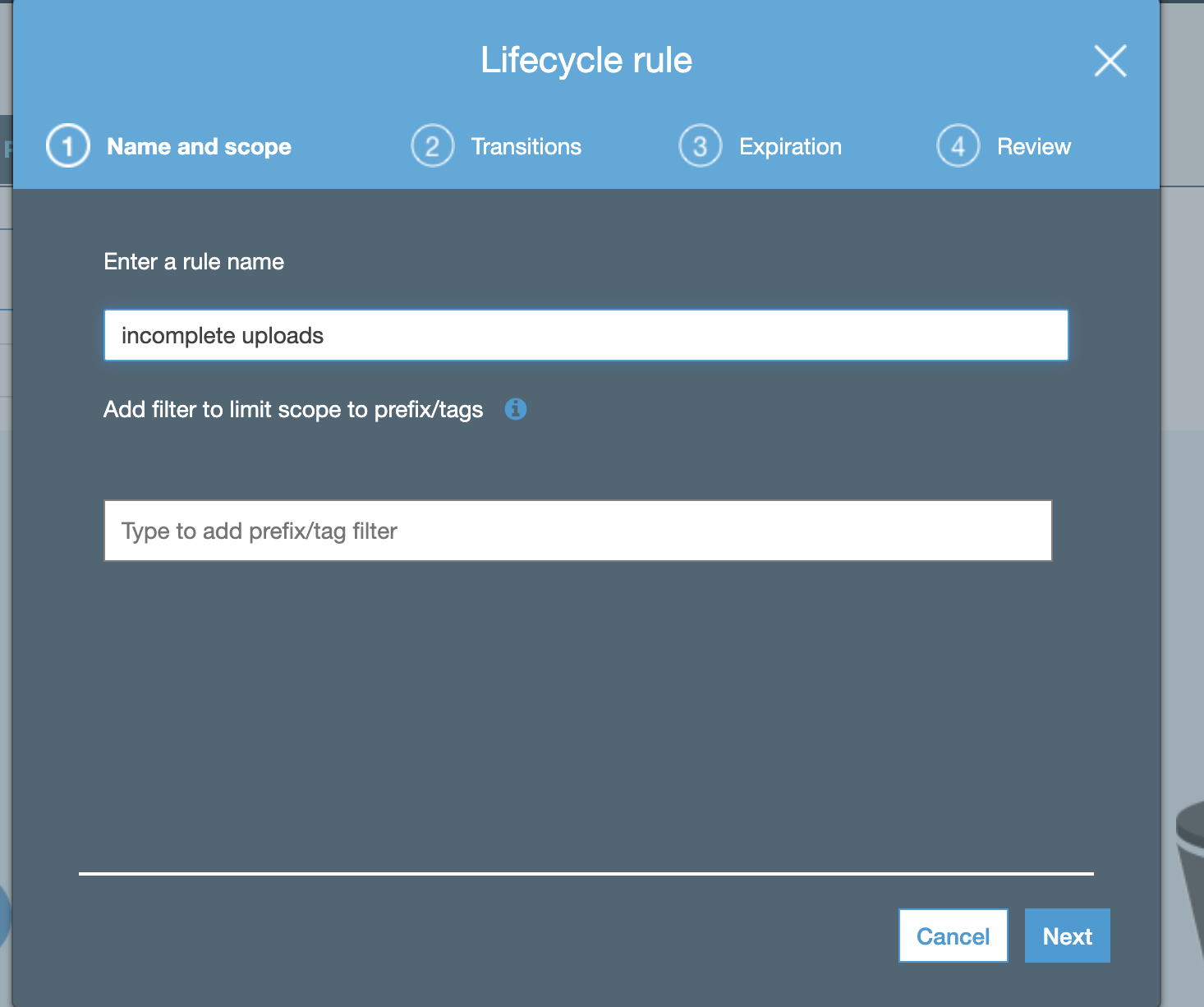
- Name the rule incomplete uploads:
-
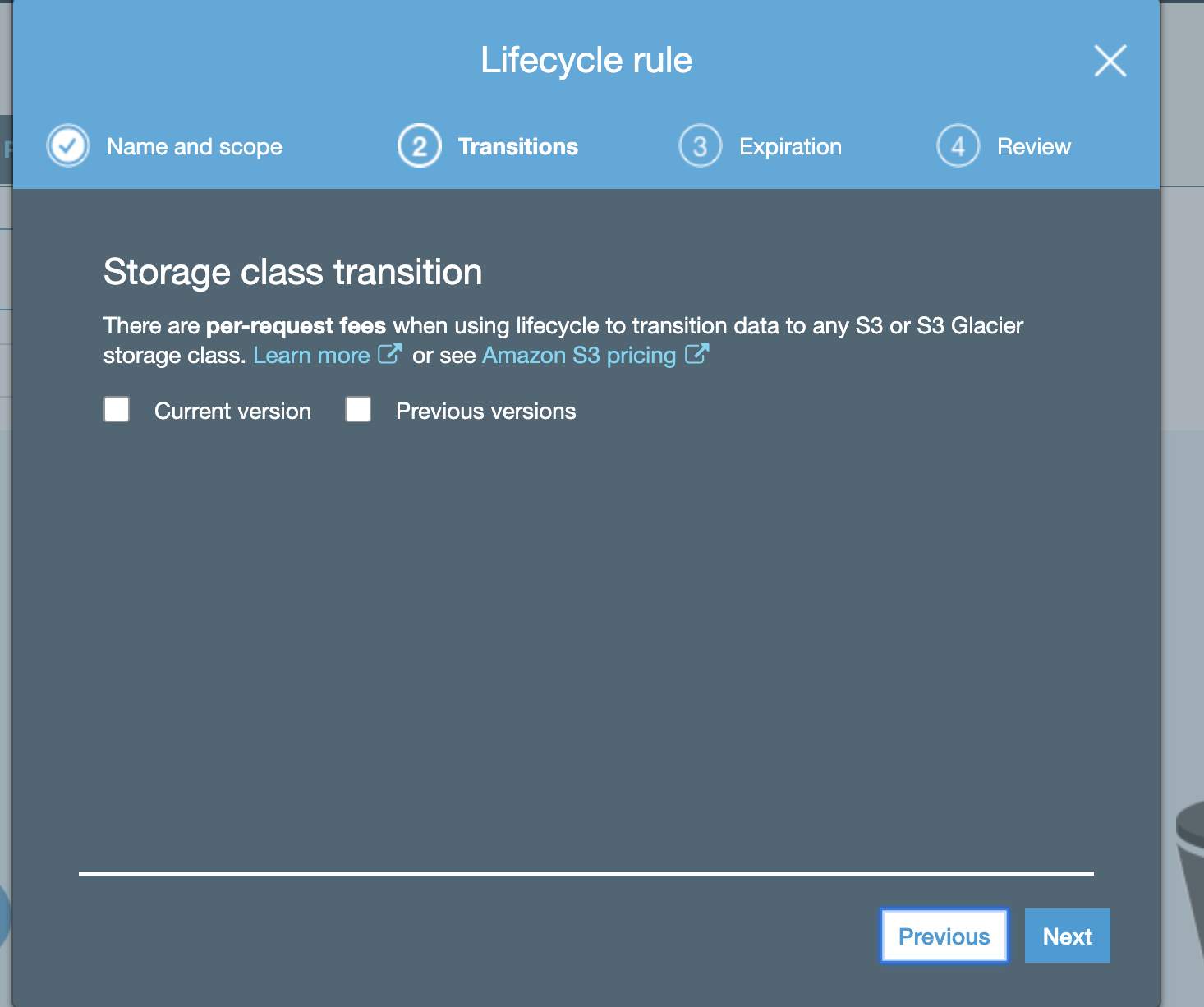
- Leave defaults on this screen:
-
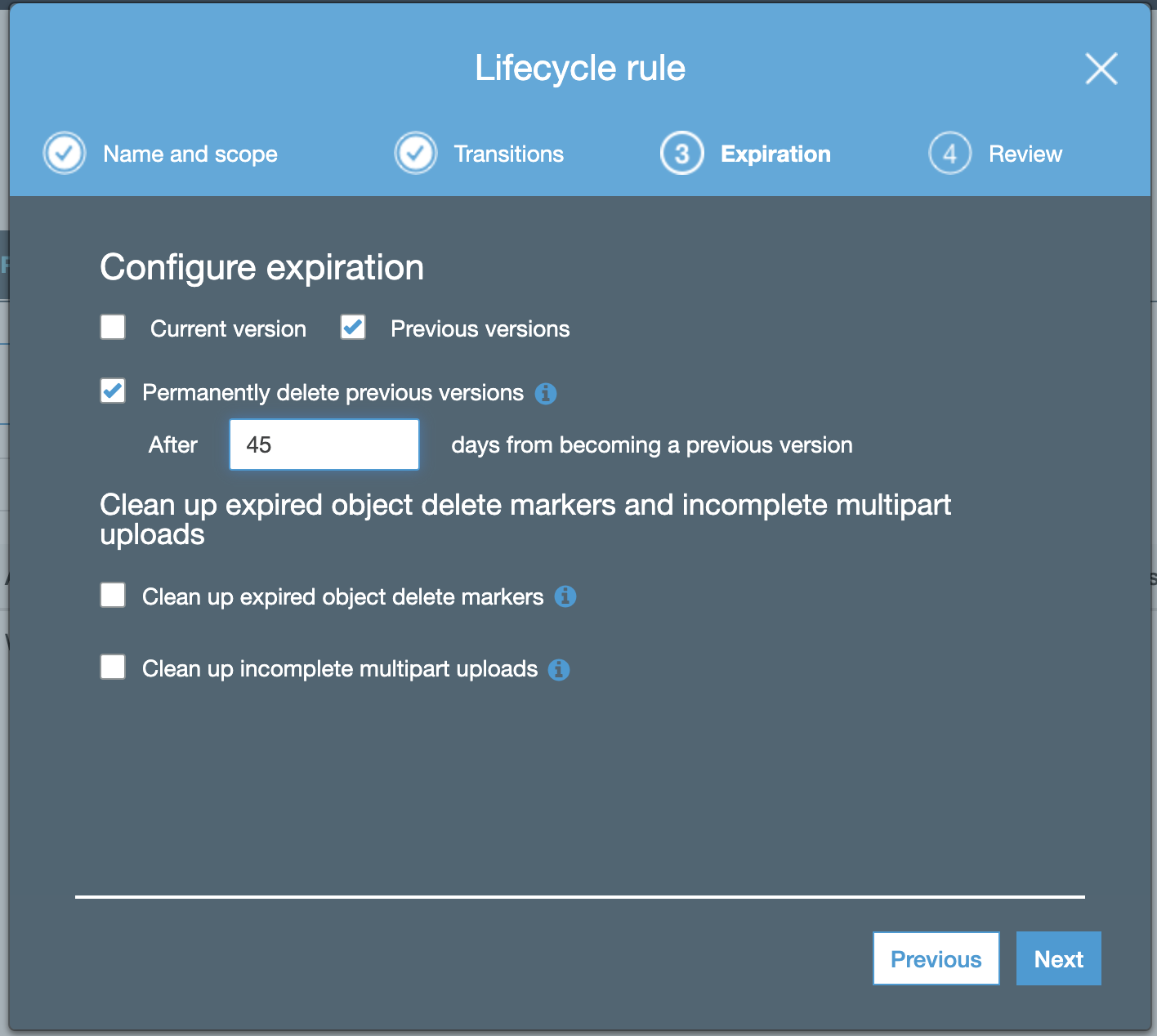
- Configure as per the screenshot below:
-
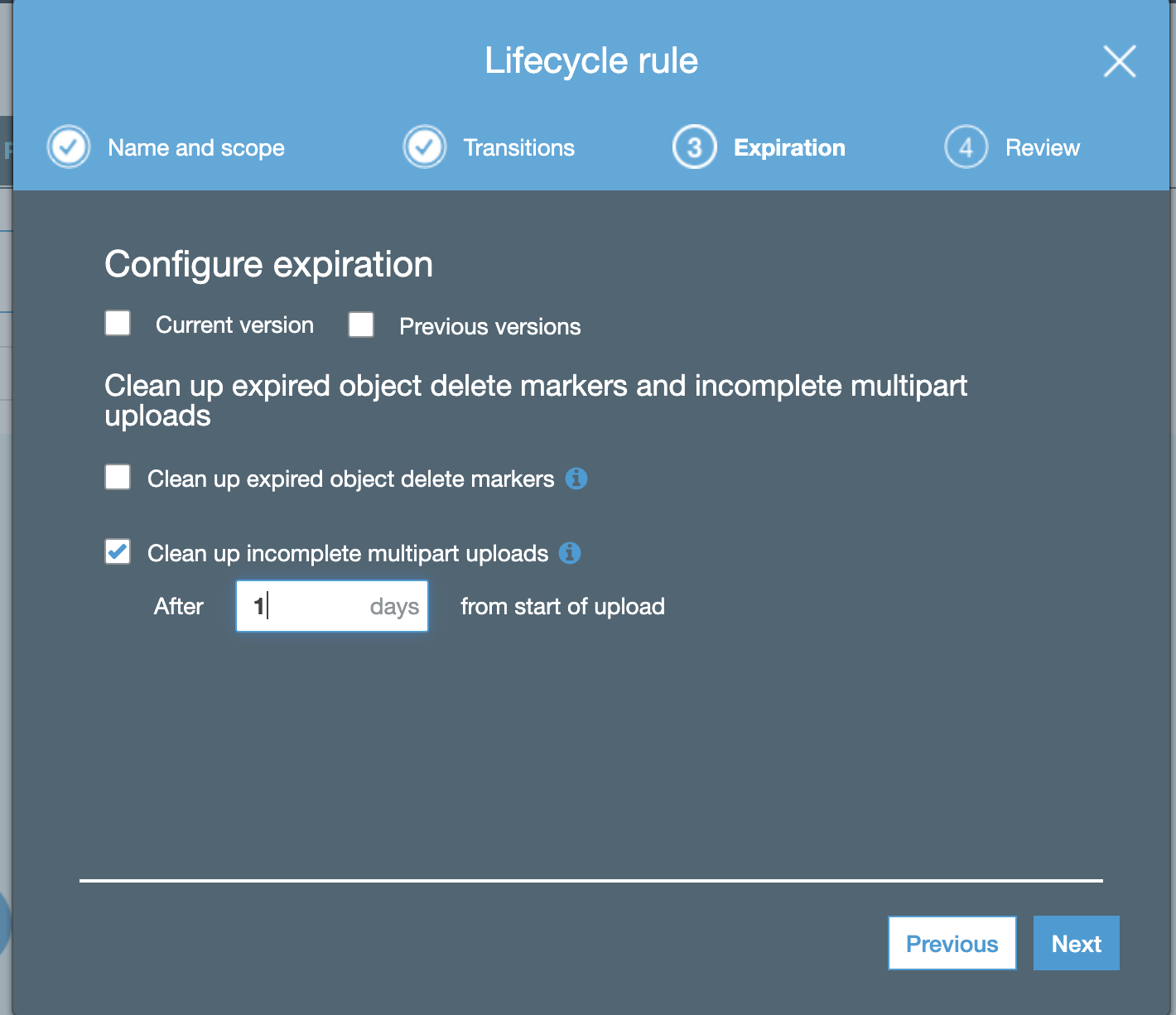
- click "Next" and save the rule.
- Done.
-
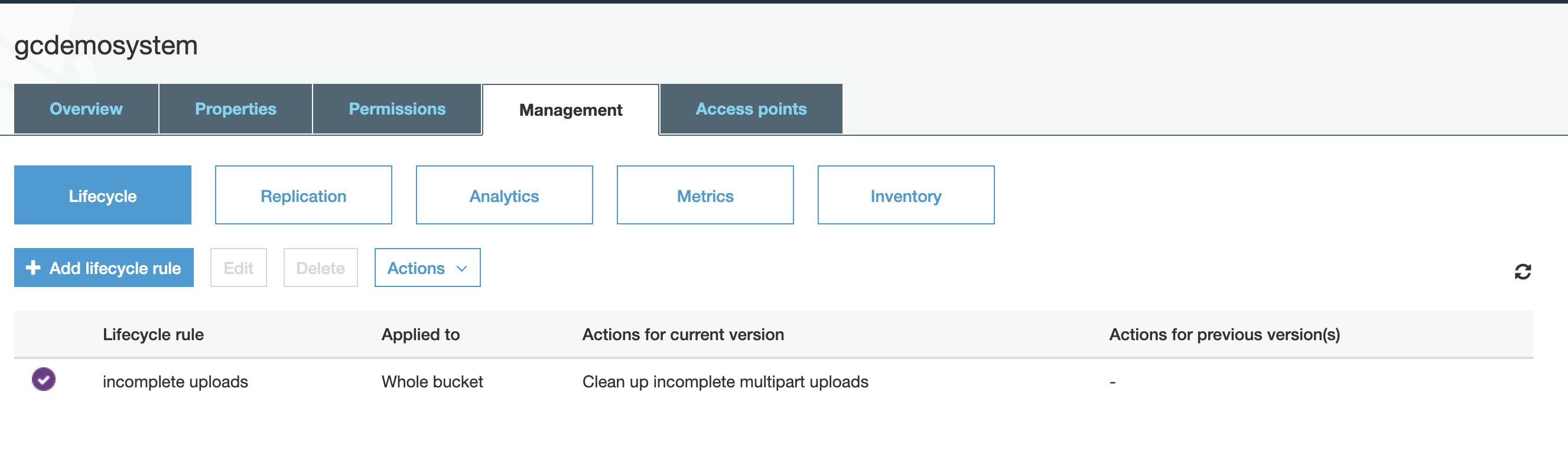
How to Configure Amazon AWS Glacier
- Glacier is an S3 service tier that offers long term long cost archive. Once an object has been moved to Glacier it will no longer be accessible from an S3 browser or by Golden Copy for restore until the inflate process has been completed.
- The steps below explain how to edit a single files storage class and how to create life cycle policy to move all uploaded data to Glacier.
How to apply single File storage class change for testing Glacier
-
Login to the Amazon S3 portal and click on a file in the storage bucket and select the "Properties" tab.
-
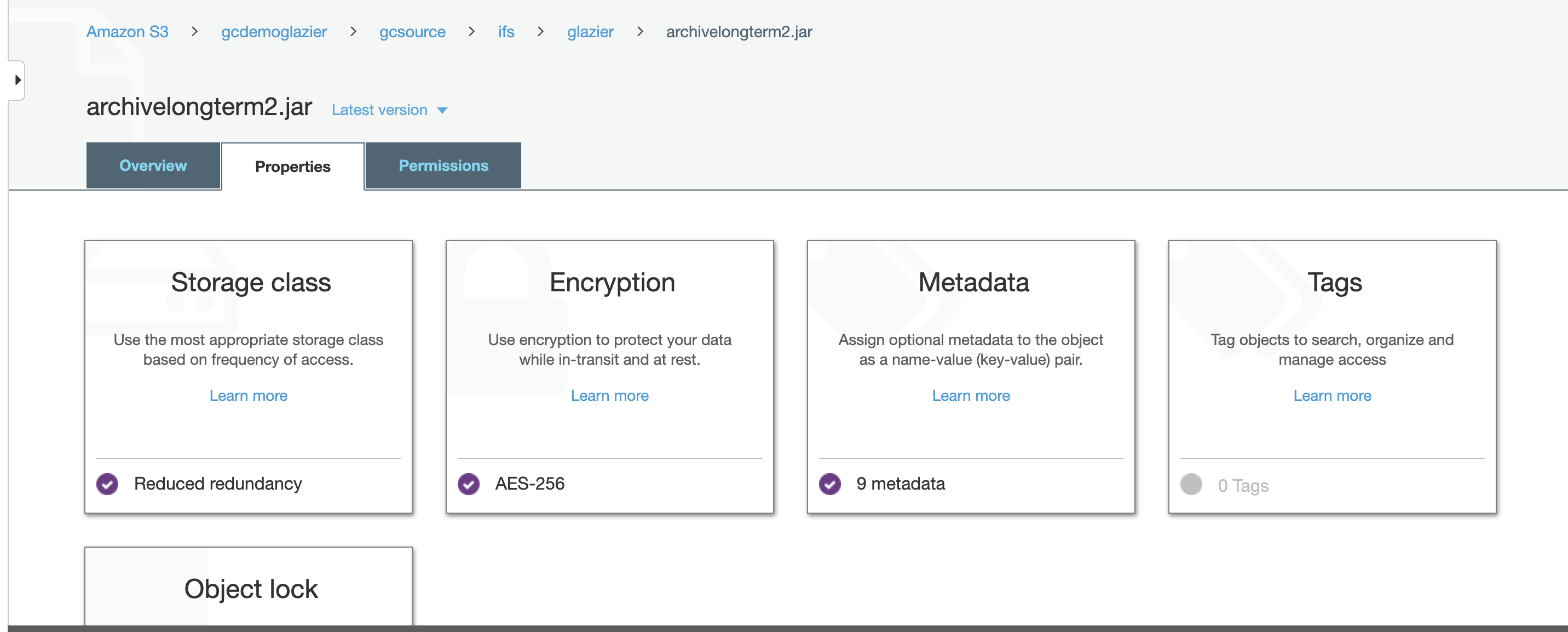
- click on the "Storage class" option, select "Glacier" and save the change.
-
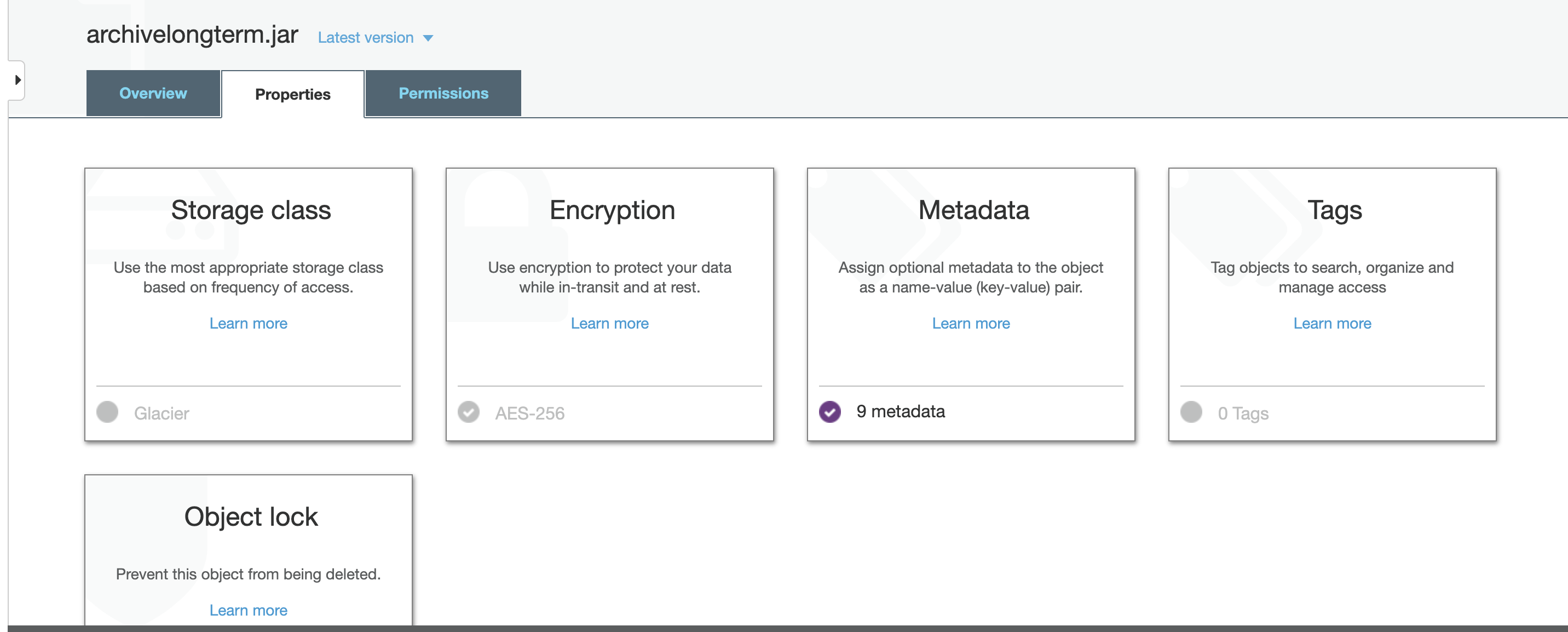
- Note: after this change the file will no longer be downloadable from an S3 browser or Golden Copy.
-
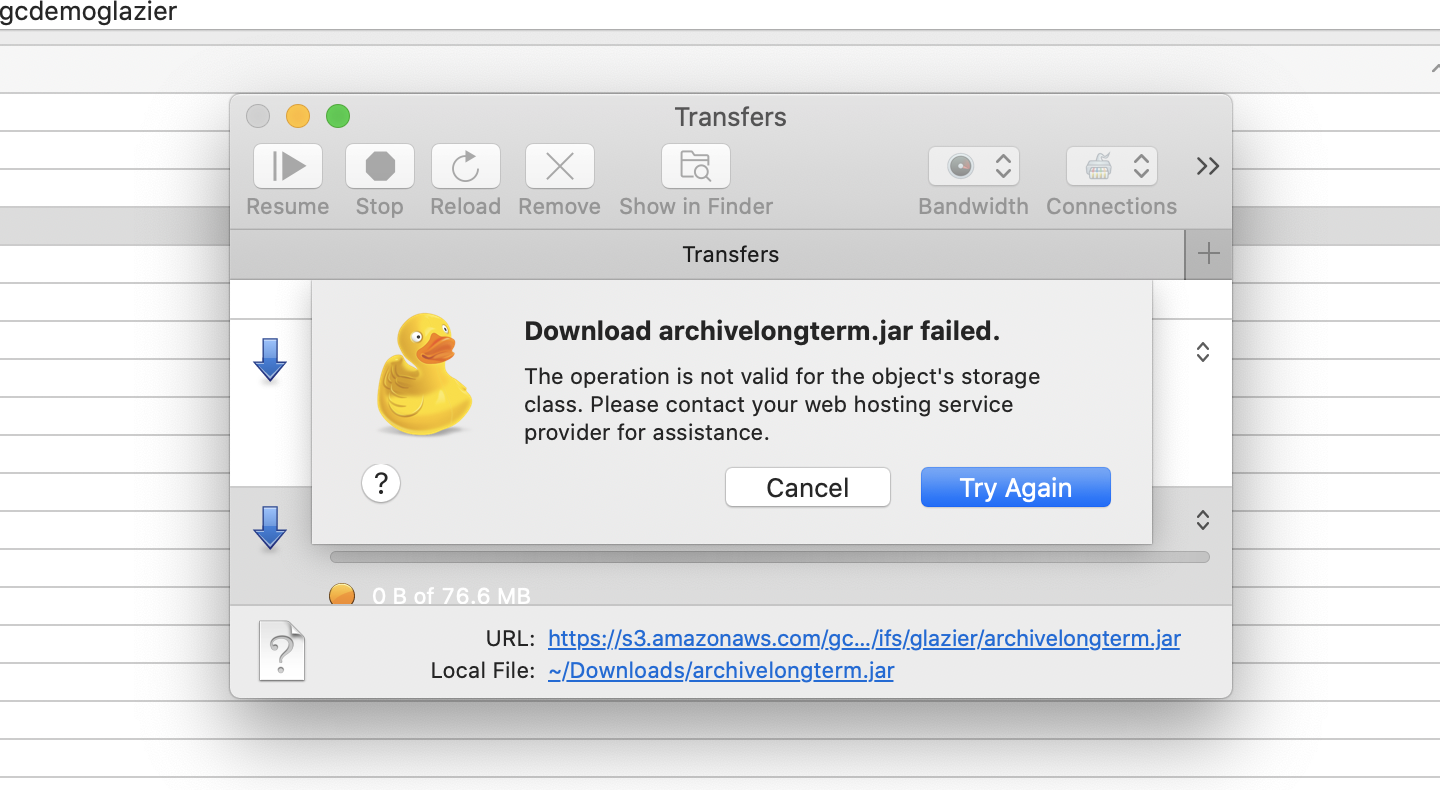
How To recall a file from Glacier:
-
Select the file in the Amazon S3 bucket and select the checkbox and click "Restore".
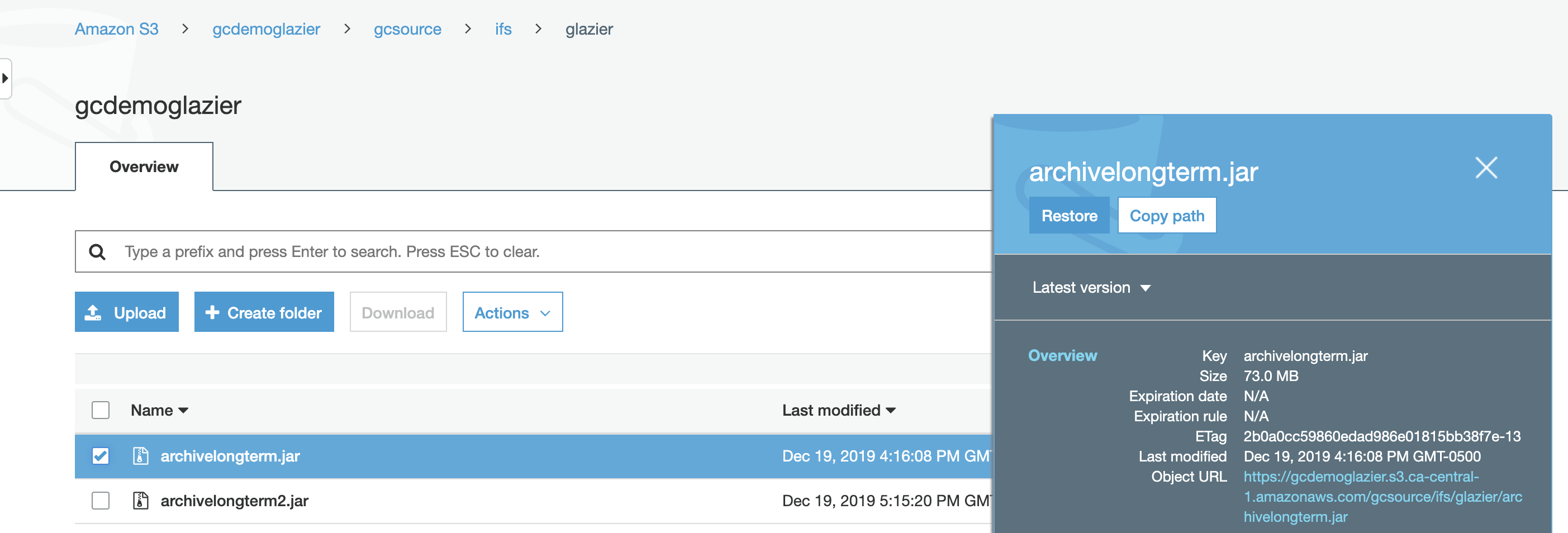
- Note: Bulk operations or api restore is possible and you should consult AWS documentation.
- Complete the restore, restore speed options and days the restored file will be available for access to submit the request.
- Once the restore has been completed, the property on the file is updated to show how long the file can be downloaded.
-
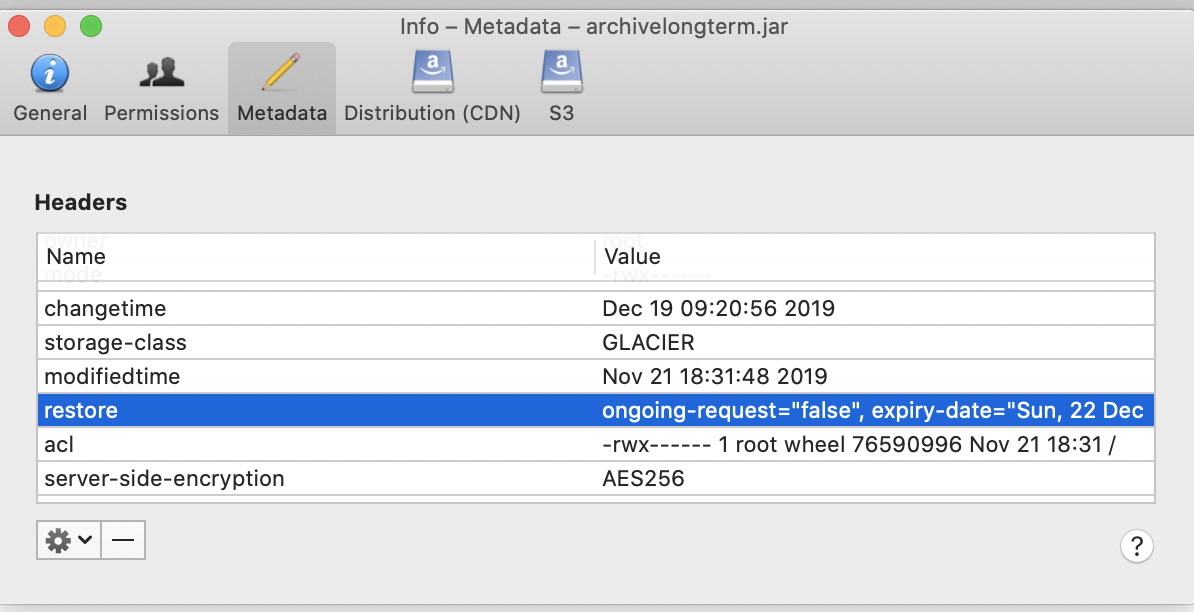
- Done.
How to configure Glacier Lifecycle policies on a storage bucket
- Select the bucket Management tab.
- Click "Add Lifecyle Rule".
- Enter a rule name.
-
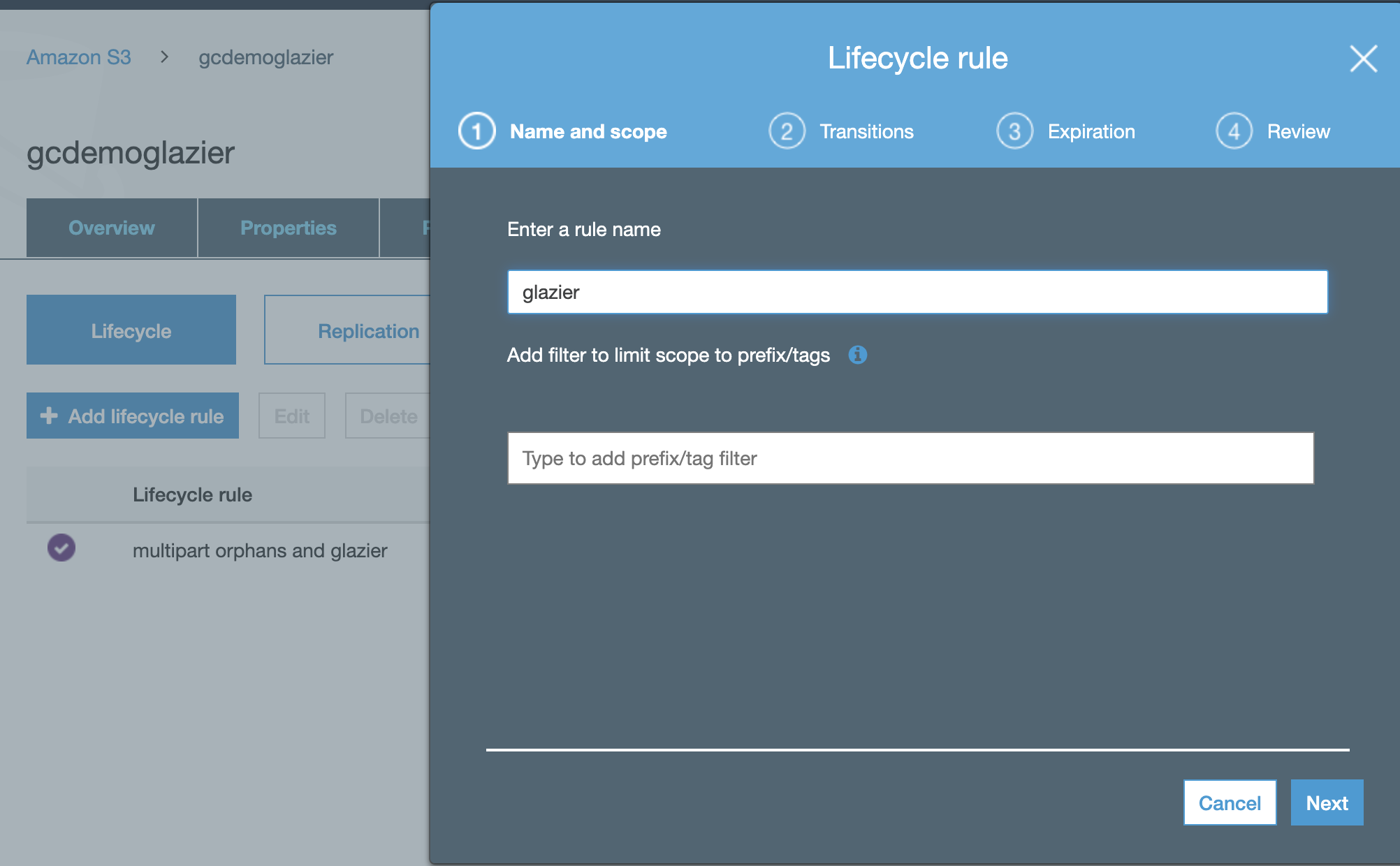
- Select "Current version" or versions check box depending on your version setting on the bucket.
- Click "Object creation" rule drop down and select Glacier
-
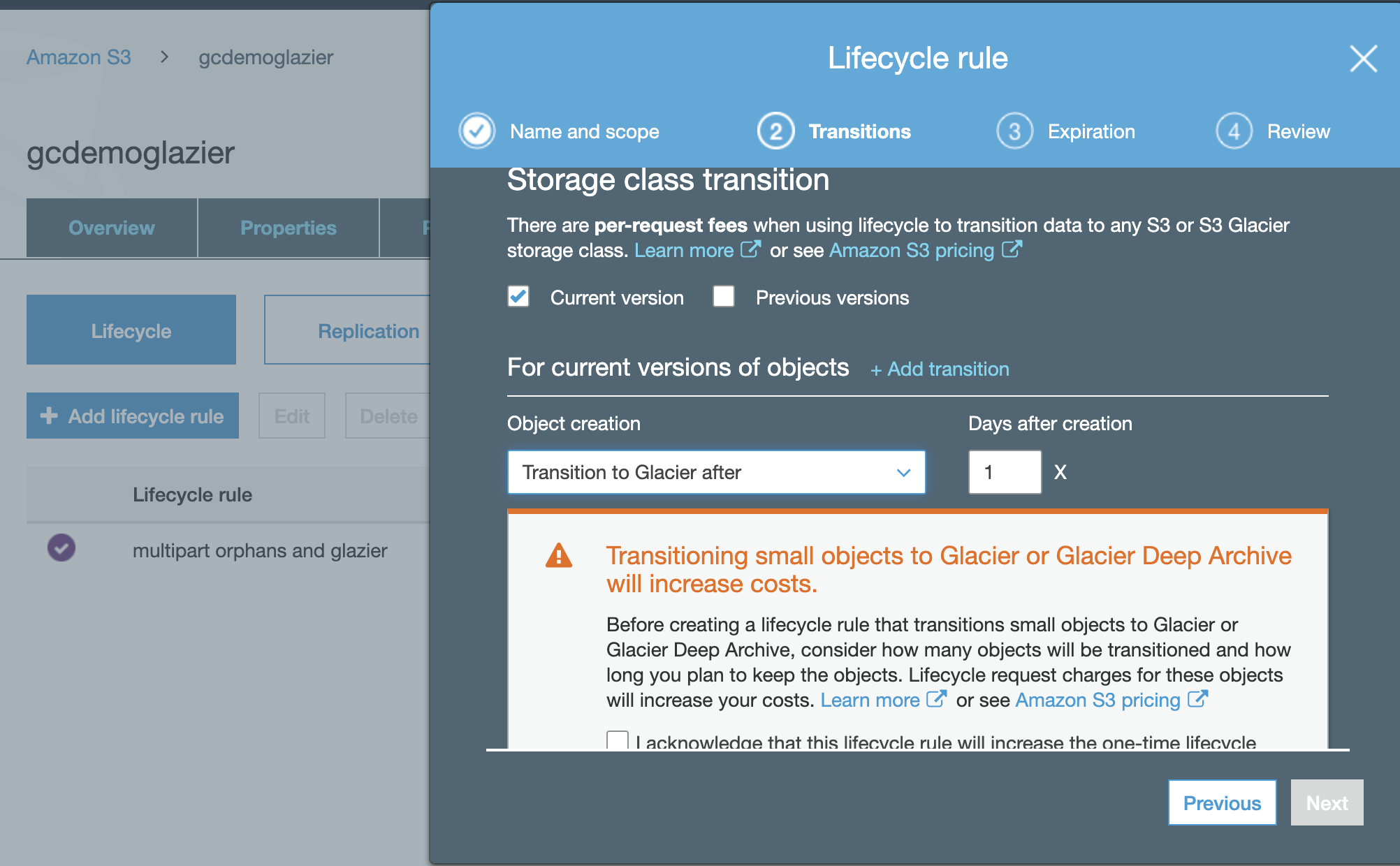
- Click "Next".
- Optional but recommended enable clean up incomplete mulipart uploads and set to 1 day
-
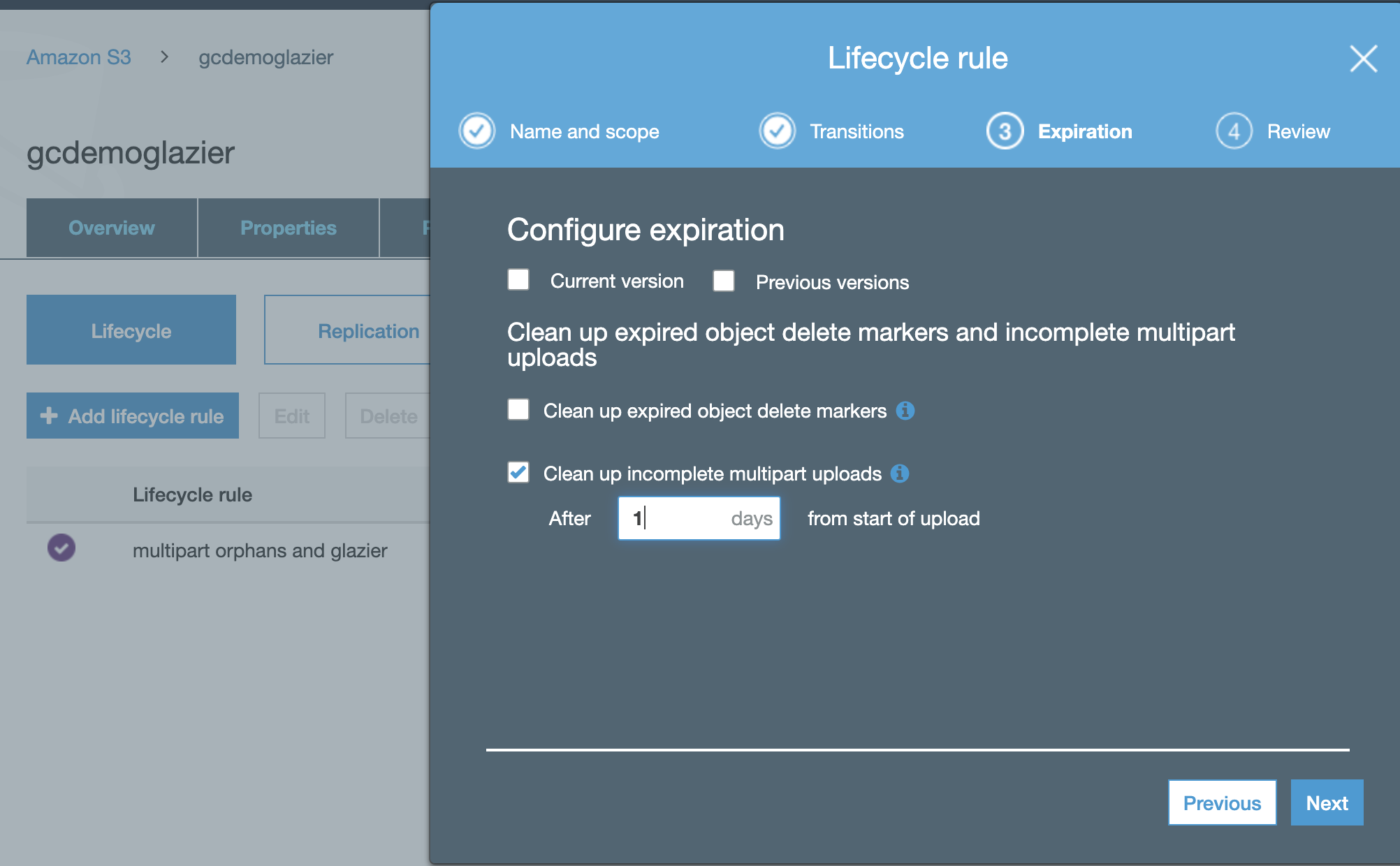
- Click "Next" and save the policy.
- Note all newly created objects will move to Glacier tier 1 day after creation.
- Done.
How to Configure Storage Tier Lifecycle Policies with Azure Blob Storage
- Centralized Azure lifecycle management allows simple policies to move large numbers of objects with policies.
- This simple guide shows how to create a storage policies to move objects based on last accessed or modified dates on the objects to determine when to move the object to a lower cost storage tier.
- https://docs.microsoft.com/en-us/azure/storage/blobs/storage-lifecycle-management-concepts?tabs=azure-portal#azure-portal-list-view
How to Monitor target storage versus your backed up source file system paths
- The procedures below can be used to monitor usage in cloud target storage versus Golden Copy folder statistics and the file system on PowerScale. It is assumed this is used for full backup and then incremental mode has been used.
- File System Reporting
- Quota's can be used to compute total data to backup on a file system path
- InsightIQ can be used to estimate the number of files on a file system path
- Cloud Storage
- Billing records will state total data stored in Cloud storage
- Most Cloud storage has tools to report on the number of objects and size of data within an S3 bucket. Use these tools to report on total quantity of data backed up.
- NOTE: If you have file versioning enabled with incrementals the amount of data backed up will be larger than the source file system path, since each new version of a file is stored at the full size of the file.
- Golden Copy
- The GUI shows the total data backed up all time, this value can be larger than the data backed up based on the file system for several scenario's include retries on failed uploads, versioning with incrementals, and whether or not deletes are enabled.
- Best Practice
- Use the File System reporting and compare to the Cloud vendor reports. Golden Copy is copying changes to the target and the source to the target comparison should always be used to validate. If the total quantity and file count is within an acceptable range then skip the steps below. NOTE: small differences in file size reporting is normal between file systems and object storage. Additional objects are copied for each folder to protect folder ACL's that you need to factor into the comparison. Example If you have 10M folders you will have additional 10M ACL objects created by Golden Copy that will make a direct file count comparison inaccurate.
- On a frequency that is determined by your internal policies we recommend an audit of folders using the Full archive mode. This will check if the source and target are in sync and copy new or modified files (it will not delete any data from the target). NOTE: Review Golden Copy cost considerations.
- At a minimum once every 6 months
- A file system compare feature also exists that will perform the same audit but it will handle deletes if an file is missing on the file system but exists in the target storage. This job type is much slower than the full archive job and should only be used if you suspect deleted data is present in the target that should be deleted. Contact support before running this job type. NOTE: Review Golden Copy cost considerations.
Supported S3 storage classes
| Storage class |
|---|
| S3 Standard |
| S3 Standard-IA |
| S3 Intelligent-Tiering |
| S3 One Zone-IA |
| S3 Glacier Instant Retrieval |
| S3 Glacier Flexible Retrieval |
| S3 Glacier Deep Archive |
© Superna Inc