- Overview of the Document Classification System
- Understanding Classification vs key Word Searching
- Best Practise (Content or Data Classification)
- Starting a Data Classification Project? Start here first
- Advantages of Data Classification
- Tag aware Indexing process
- How Classification and Tagging Works
- Regex Syntax to Follow
- Classification Use Cases
- How to enable Classification Tagging without Content Indexing
- How to Configure a Classification Rule
- How to list classification rules
- How to add a new classification rule
- How to modify an existing classification rule
- How to remove a classification rule
- How to View the rules file
- How to test a file with your Classification rules before production Role out
- How to Use Test data and commands to use to Experiment with Data Classification
- Common Compliance Standards Overview
- PII and Sensitive PII Defined
- Security Classification Schema For PII
- How to use RegEx Expressions to Locate Compliance Data
- Regex Expression Testing Tools
- Basic Regex Syntax for Most Scenarios
- Tested RegEx Expressions
- Identify Executable Files
- Files with URL's
- Document Security Classification
- Name
- Address
- Street Address
- North American Street Address
- German Street Address
- State, Region or Province
- State, Region or Province Key Words
- French Province
- Italian Region or Province
- Spain
- UK
- Canadian Province
- US State
- US Zip Code
- Telephone Number Key Words
- French Telephone Number
- Italian Telephone Number
- Spanish Telephone Number
- UK Telephone Number
- North American Telephone Number
- Social Insurance Number
- Social Insurance or Social Security Key Word
- French Social Insurance Number
- Italian Codice Fiscale
- Spanish Social Insurance
- NIE (Número de Identificación de Extranjero) for non Spanish Citizens
- DNI (Documento Nacional de Identidad) for Spanish citizens
- UK NINO
- Canadian Social Insurance Number
- US Social Security Number
- Date of Birth
- IBAN: Europe Only
- Bank Account Numbers
- Germany
- France
- Italy
- Spain
- Bank Account Numbers: Canada and US only
- Account Numbers Canada and US
- Bank Account Number US (10 - 12 digits) and Canada (7- 12 digits)
- US
- Canada
- Bank Routing Numbers
- US Routing Number
- Canadian Routing Numbers
- Routing and Bank Account Numbers
- US
- Canada
- Credit Card Number
- ACH Format Compliance Check
- Credit Card CVV
- Expiration Date
- Medical Data
- Medical Record Number (MRN)
- Weight
- Height
Overview of the Document Classification System
This guide covers different classification types that can be located in documents and the ability to configure the classification feature to read documents and match to classification types that are configured and apply a tag to the custom classification attribute in the search schema. This allows simple easy searches and scheduled reporting on compliance data. This allows aggregate reports and file lists for data that has been tagged by the classification system
Once the tagging configuration is in place, full scan index can tag existing data and incremental mode can detect new documents or modified documents and scan the documents for compliance data. This feature automates the whole process and reduces the complexity and time spent classifying data.
This feature can be used with custom tags for internal document classification for any vertical industry that has specific document types. This system is flexible to tag documents based on regex syntax matching that supports substitution and wild card for letters numbers in documents.
Understanding Classification vs key Word Searching
Key word searching is typically used for legal discovery to locate files needed for a specific investigation. It can also be used for end user search solution where users are locating documents based on key words. This includes adhoc searches for key words.
Data Classification focuses on locating well known data types within documents to ensure it has been secured correctly and the correct users have access to the information. Data Classification solutions search for well known data types such as credit cards for PCI, personal information such SIN number, drivers license, email address, addresses, health records. The data is typically employee data or customer data. Data classification is often alpha numeric patterns and this is best addressed with regex pattern matching.
Data Classification requires reading the content of the files and locating matching patterns for well known data types based on the specific compliance requirements. Solutions must be able to read many different file types, Search & Recover supports over 1500 file types. As business requirements change it is necessary to update the classification pattern matching policies.
Data Classification requires reading files each time a new classification tag is added, this requires rescanning the path in the file system. The data remains in the file system and is not copied into the index. This would require too much disk space to store the data in the index, an index does not store the documents themselves and only stores pointers to words in specific documents. All Data Classification systems must scan files in the file system itself to save space in the index and not duplicate the files in the index.
Search & Recover allows incremental scanning for new or modified files to be scanned quickly due to integration with Powerscale change list feature. For cold data a path scan is required and can be targeted anywhere in the file system with an index job that specifies a path to start the scan for new Data classification tags add to the system.
Best Practise (Content or Data Classification)
- Full Content indexing for adhoc unknown search requirements
- Data Classification to tag documents for compliance data identification or any alpha numeric pattern matching.
Starting a Data Classification Project? Start here first
- Data classification requires a list of PHI or specific data tags needed before you start creating production rules in Search & Recover. As per above explanation scanning the file system should be done once all rules are created and tested with test data.
- List all data types needed
- Map out tags for reporting on each type of data
- Create test rules using examples in this guide
- Create test data with good and bad matches for testing.
- Follow the rules test feature to test matching logic quickly and easily. Link here.
- You can also test with our test data and rules. Link here.
- Modify your rules and test until you are ready to move into production.
- Once you are in production, we suggest copying your test data to a path that is covered by a full index path policy in Search & Recover. Then use the index on demand command to index your data without waiting for the next scheduled index job.
- searchctl folders list (to get the folder id)
- searchctl folders index --id xxxx --incremental
- Then watch the job
- searchctl jobs view --id xxxx (user the job name provided from the index command)
- Wait for the job to complete
- Search in the GUI using the quick report "Data Classification" See guide link
Advantages of Data Classification
- Reduction in disk space vs full content indexing
- Faster producing of content to locate data based on pattern matching
- Supports more complex pattern matching and number aware matching syntax with regex
Tag aware Indexing process
- Tag aware processing allows dynamic tracking of files and determines if a file has been scanned against the tag classification filters. The system will determine if any new classification filters have been created and will determine if a file needs a rescan.
- Full scan or incremental jobs both enable dynamic classification tag detection to intelligently scan files that have not been scanned for a new classification filter.
How Classification and Tagging Works
- The classification uses regex to process all the text that is provided by the content indexing engine when a full or incremental folder scan runs with content ingestion enabled in classification mode.
- The text of each document is decoded and sent to the classification engine.
- The classification engine is configured with regex rules below to locate compliance data and apply a tag to the document in the index.
- The tag name is specified in the classification rule.
- A document can match more than one classification rule and will have more than one tag applied.
- The text of the document is not indexed or stored in the index which reduces the space needed in the index. NOTE: no key word searches will be possible unless full content indexing is enabled in addition to classification mode.
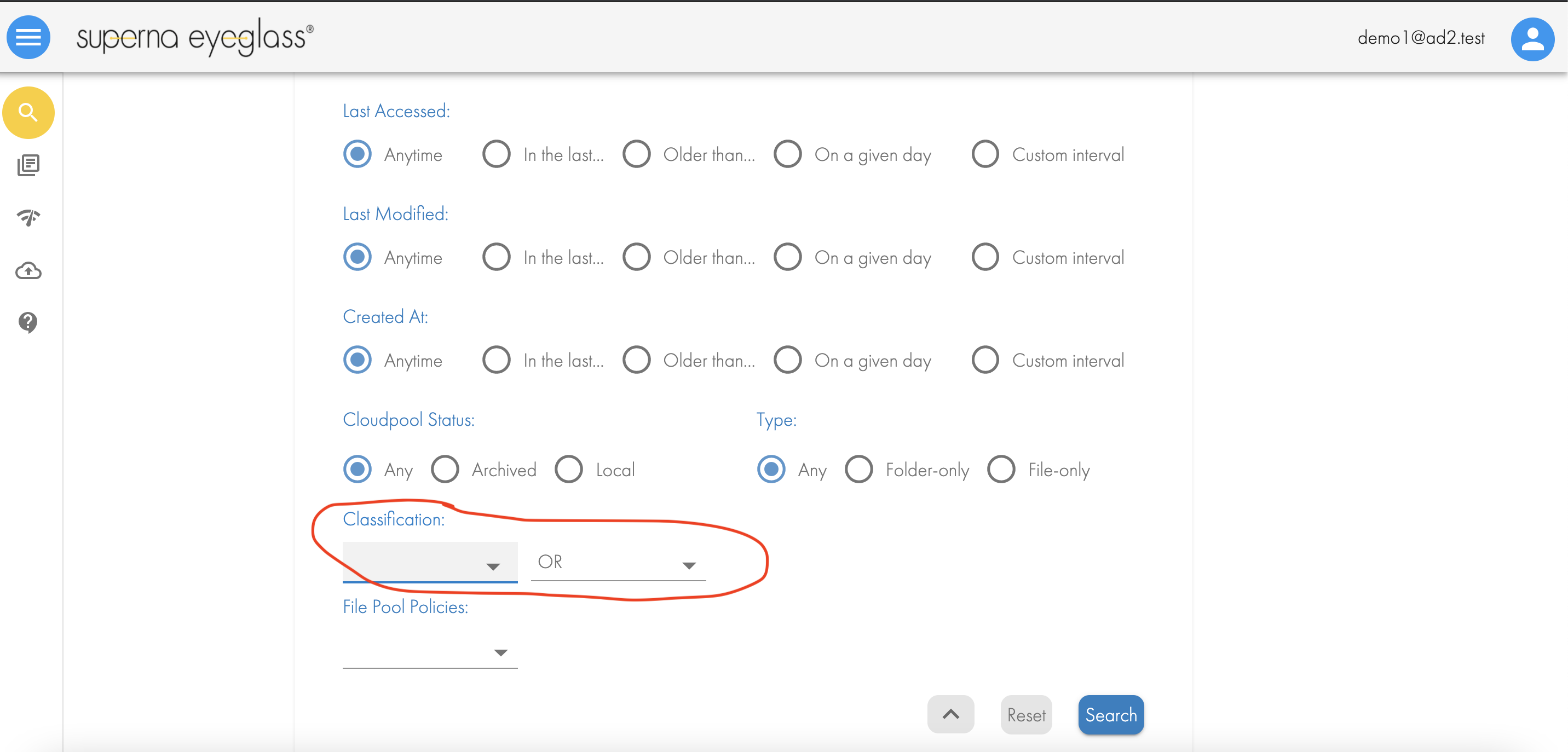
- Once a document is tagged you can use the classification option in advanced search or quick reports to narrow your search results to documents that match a specific tag.
- See example below, the list of tags will be available with the option to combine them with AND/OR search logic with multiple tags and can multi select tags.
-
Regex Syntax to Follow
- Regex engines can vary. The rule set to follow is the Java regex engine. This table shows syntax and escape characters to use.
- https://gist.github.com/CMCDragonkai/6c933f4a7d713ef712145c5eb94a1816#feature-comparison
Classification Use Cases
-
New Search & Recover Deployment
- Index metadata and leverage content aware data classification without storing indexed content in the database. This option does not require expanding disk space to store classification tags. Disable full content index storage following steps here.
-
Existing Deployment with Content Indexing Enabled
-
In the initial release of 1.1.5 tags can not be applied unless data is re-indexed and stored in the database. The presence of a classification tag configuration will trigger the re-index process to force a full re-index of content to be scanned for tags and the file will be re-added to the index even if the file on disk has not changed since it was last indexed. This will take time to re-index. This requirement should be considered before using this feature.
-
In the initial release of 1.1.5 tags can not be applied unless data is re-indexed and stored in the database. The presence of a classification tag configuration will trigger the re-index process to force a full re-index of content to be scanned for tags and the file will be re-added to the index even if the file on disk has not changed since it was last indexed. This will take time to re-index. This requirement should be considered before using this feature.
How to enable Classification Tagging without Content Indexing
- Use this option to enable classification when full content indexing is not required. This option has no additional disk space requirements other than the metadata index sizing guidelines.
- Login to node 1
- nano /opt/superna/eca/eca-env-common.conf
- paste this to the file
- export ADD_CONTENT_TO_INDEX=false
- control+x to save
- ecactl cluster down
- ecactl cluster up
- done
How to Configure a Classification Rule
-
Each classification rule is added to a single file and evaluated against the text of each file processed for content and classification processing.
-
Login to Search & Recover node 1 as ecaadmin
-
searchctl CLI commands will be added to edit this file and live update the ingestion engine to start using the new rules file. The below information is information to validate your rules file.
-
How to list classification rules
-
searchctl classification list
-
-
How to add a new classification rule
-
searchctl classification add --name NAME --regex REGEX | [--regex-file /home/ecaadmin/regex.txt]
-
--name - this is the name of the tag that will appear in the GUI when searching. Use single quotes at the beginning and end of the tag name.
-
--regex - this is the regex value used to match text for this tag. See examples in this guide or create your own regex matching string. Use single quotes at the beginning and end of the regex pattern.
- (optional) --regex-file <path to file > This flag should be used for any complex regex with special characters that cannot be passed into the CLI command due to bash shell restrictions. The regex in the file can use any special characters needed.
-
-
example
-
searchctl classification add --name 'email' --regex '[\\w-\\.]+@([\\w-]+\\.)+[\\w-]{2,4}'
-
-
-
How to modify an existing classification rule
-
searchctl classification modify --name NAME --regex REGEX
-
Enter an existing tag name and new regex value to replace the matching logic.
-
-
How to remove a classification rule
-
This command will start a job that searches the index for the files matching the tag and will place these files in a queue to re-index the files. This second re-index will no longer be tagged with the removed tag. This job can add a lot of files to be processed and will take time to remove them from the index. Once the command is executed the GUI will no longer display the tag for searching.
-
searchctl classification remove --name NAME
-
NOTE: A job is launched to submit all matching files to be re-indexed, this will re-read the content of these files and run match rules for all remaining tags. This can generate read bandwidth to re-process these files and re-read all files to retag the files based on remaining data classification rules.
-
-
-
How to View the rules file
-
cat /opt/superna/eca/data/classifiers.json
-
{
"email":"[\\w-\\.]+@([\\w-]+\\.)+[\\w-]{2,4}",
"phone":"(\\+\\d{1,2}\\s)?\\(?\\d{3}\\)?[\\s.-]\\d{3}[\\s.-]\\d{4}",
"ipv4":"(([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\\.){3}([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])"
}
How to test a file with your Classification rules before production Role out
-
This feature allow testing your classifiers easily with a single command
-
Example:
-
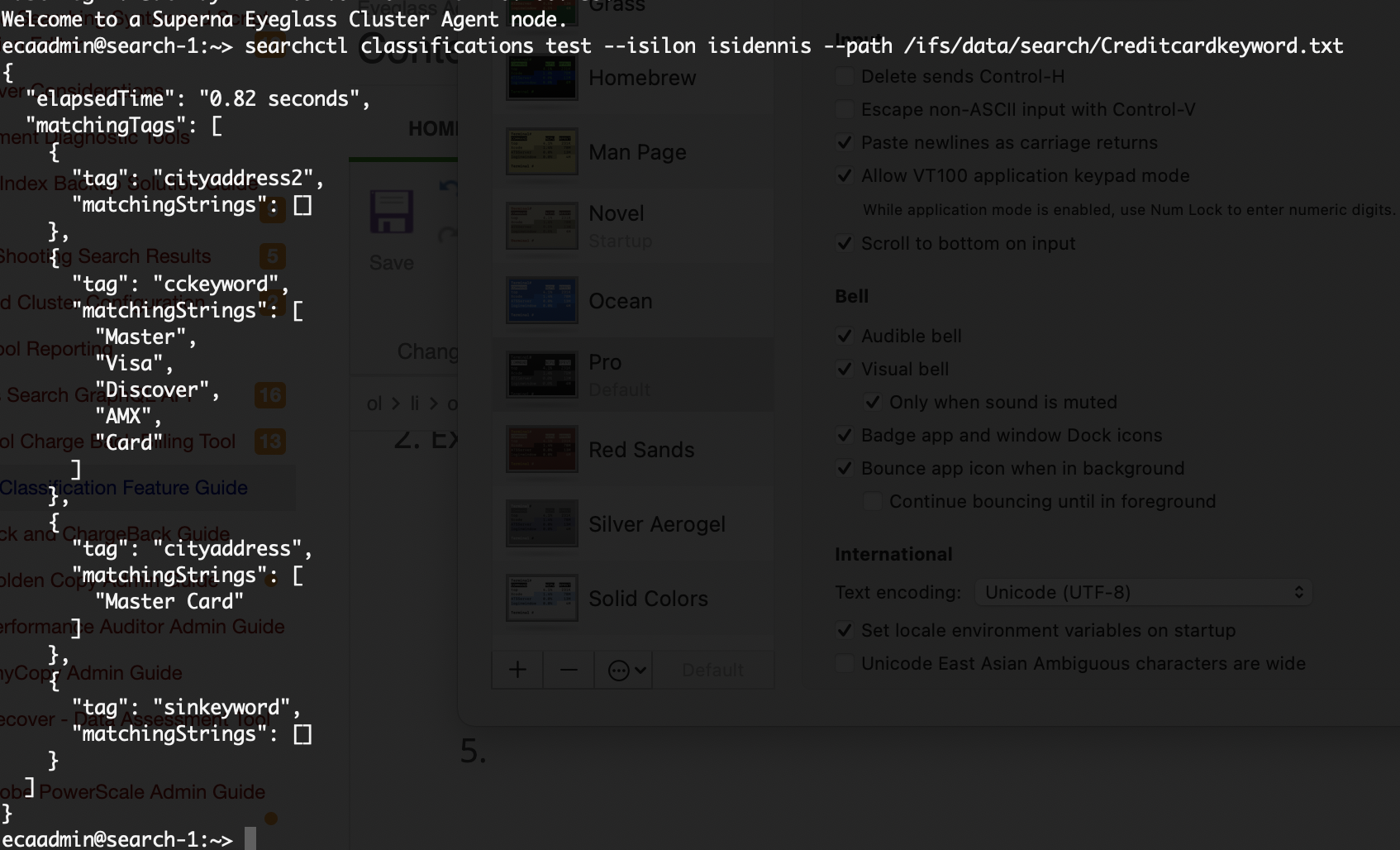
searchctl classifications test --isilon <cluster name> --path /ifs/data/search/filetotest.txt
-
Retrieves the file over the rest API.
-
Tests the content of the file against all configured classifications
-
Prints to the console which classifications matched and which string was found
-
See example below that shows which tags matched and which strings in the file matched the regex
-
-
How to Use Test data and commands to use to Experiment with Data Classification
- Download test file data and Excel sheet inside the zip file.
- Unzip the file and copy the word documents to a test SMB share
- Configure indexing on this folder path
- Open the Excel file from the zip file named Regex Tag and Test File Map.xlsx
- Use column A to copy and paste any of the classification commands to your search appliance based on which classifications you want to test with. Each row shows which files will match this classification tag.
- Start an index job on the test path.
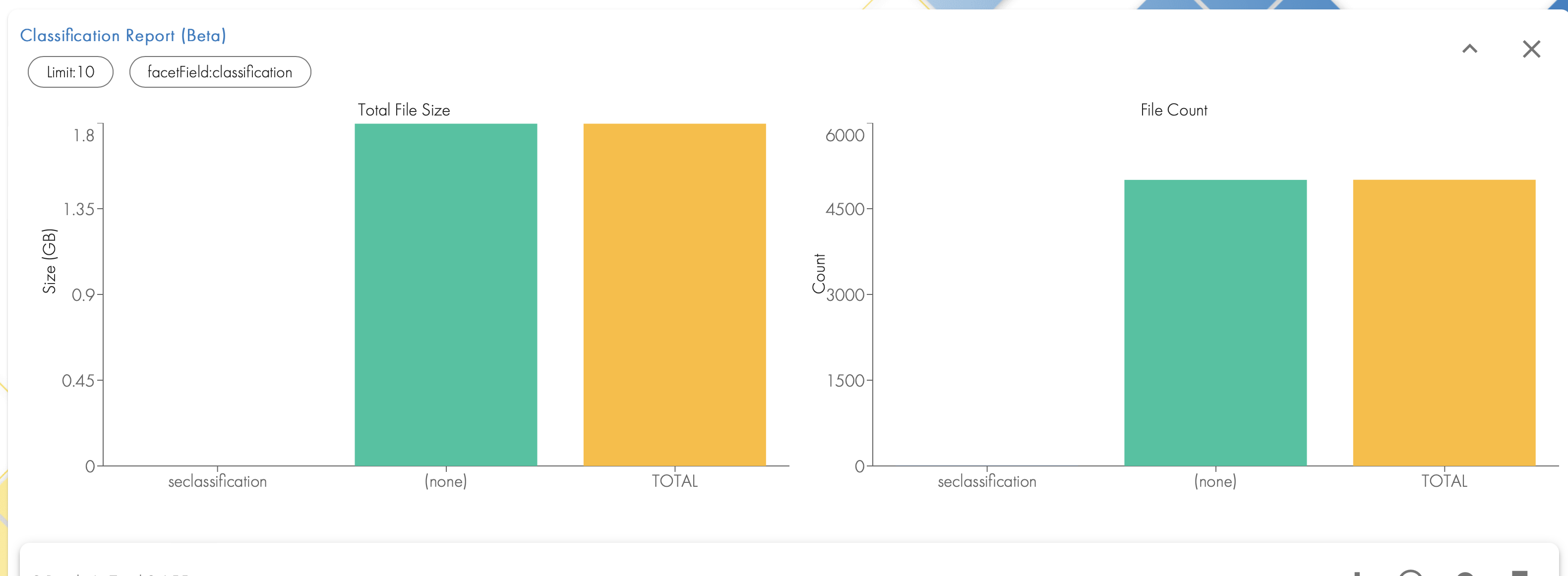
- Login to the GUI and click on the quick reports tab.
- Run the "Classification Report"
- In the table below the graph you can select a tag and chose the show me the files option to locate the tagged files.
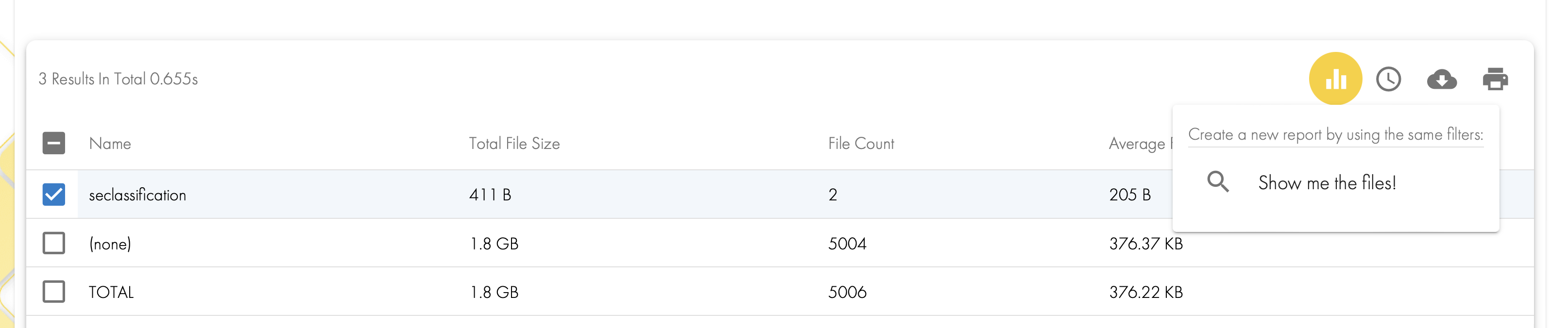
- Done
Common Compliance Standards Overview
Businesses are collecting and storing more and more individuals’ PII. As a result, various jurisdictions have passed legislation to limit the use, distribution, and accessibility of PII, while allowing companies who need it to manage the data safely. GDPR in the European Union, HIPAA (Health Insurance Portability and Accountability Act ) and PCI DSS (Payment Card Industry Data Security Standard) in the United States, along with state laws, other data breach laws, and other regulations control what defines PII.
The most common compliance standards covered below provides background on the key requirements to locating and protecting data that falls into one of these categories.
PCI DSS provides standards for the processes and systems that merchants and vendors use to protect information. This information includes: Cardholder data such as the cardholder's name, the primary account number, and the card's expiration date and security code.
PHI is any health information that can be tied to an individual, which under HIPAA means protected health information includes one or more of the following 18 identifiers. If these identifiers are removed the information is considered de-identified protected health information, which is not subject to the restrictions of the HIPAA Privacy Rule.
-
Names (Full or last name and initial)
-
All geographical identifiers smaller than a state, except for the initial three digits of a zip code if, according to the current publicly available data from the U.S. Bureau of the Census: the geographic unit formed by combining all zip codes with the same three initial digits contains more than 20,000 people; and the initial three digits of a zip code for all such geographic units containing 20,000 or fewer people is changed to 000
-
Dates (other than year) directly related to an individual
-
Phone Numbers
-
Fax numbers
-
Email addresses
-
Social Security numbers
-
Medical record numbers
-
Health insurance beneficiary numbers
-
Account numbers
-
Certificate/license numbers
-
Vehicle identifiers (including serial numbers and license plate numbers)
-
Device identifiers and serial numbers;
-
Web Uniform Resource Locators (URLs)
-
Internet Protocol (IP) address numbers
-
Biometric identifiers, including finger, retinal and voice prints
-
Full face photographic images and any comparable images
-
Any other unique identifying number, characteristic, or code except the unique code assigned by the investigator to code the data
The data subjects are identifiable if they can be directly or indirectly identified, especially by reference to an identifier such as a name, an identification number, location data, an online identifier or one of several special characteristics, which expresses the physical, physiological, genetic, mental, commercial, cultural or social identity of these natural persons. In practice, these also include all data which are or can be assigned to a person in any kind of way. For example, the telephone, credit card or personnel number of a person, account data, number plate, appearance, customer number or address are all personal data.
Classifying and Securing PII
PII and Sensitive PII Defined
PII: NIST 800-122 defines PII (Personally Identifiable Information) as any information that permits the identity of an individual to be directly or indirectly inferred, including any other information that is linked or linkable to that individual, regardless of whether the individual is a U.S. citizen, legal permanent resident, visitor to the U.S., or employee or contractor to a government agency or corporation.
Sensitive PII (SPII): According to the US Department of Homeland Security Handbook for Safeguarding Sensitive PII is Personally Identifiable Information, which if lost, compromised, or disclosed without authorization, could result in substantial harm, embarrassment, inconvenience, or unfairness to an individual. Sensitive PII includes:
-
Social security numbers
-
Bank account numbers
-
Passport information
-
Healthcare related information
-
Medical insurance information
-
Student information
-
Credit and debit card numbers
-
Drivers license and State ID information
Security Classification Schema For PII
In order to comply with the various restrictions in place covering the security of PII at least three levels of security classifications are recommended: Public, Private and Restricted.
1. Public Data is PII data that is in the “public domain”, which includes data found in public records, public telephone directories, business directories, business cards, newspapers, social media platforms and websites. While anyone can access this data, access controls to prevent it’s unauthorized use is recommended. If an individual does not want the data disclosed it should be classified as Private Data. If it’s linkable to disassociated data such as name, address, social insurance, bank account, credit card and medical record data, it should be classified as Restricted Data.
2. Private Data is PII data an individual may not wish to disclose, such as date-of-birth, home address and phone number. Private data should be covered by a moderate level of protection. If it is linkable to disassociated data such as name, address, social insurance, bank account, credit card and medical record data. It should be classified as Restricted Data.
3. Restricted Data is sensitive PII (SPII), and is data which cannot obtain through legitimate means. Restricted data includes social insurance numbers, bank account, credit card details, medical information, etc. Restricted data should be covered by the highest level of security controls.How to use RegEx Expressions to Locate Compliance Data
The following are Regex expressions that will help to identify data as defined by PII, CPI, PHI and GDPR standards. All of these expressions have been tested using a mock database containing data for Germany, France, Italy, Spain, UK, Canada and US. The mock data Included:
-
Document Security Classification
-
Name
-
Address (Street, City, State or Province)
-
Postal Code
-
Telephone
-
Email
-
Date of Birth
-
Social Insurance Number
-
Bank Account (Account Number, Routing Number, IBAN Number)
-
Credit Card (number, CVV, Exp Date)
-
Medical Record Number
-
Blood Type, Height
Regex Expression Testing Tools
A regex is a string of text that allows you to create patterns that help match, locate, and manage text.
The https://regex101.com/ test site was used to test and validate all the following expressions:
Basic Regex Syntax for Most Scenarios
-
The following regex examples can be used for most matching scenarios. Use these examples to build your own rules.
-
Case insensitive matching
- (?i)xxxxx - Using (?i) and then a string will match the string regardless of case
-
Combining key words with OR logic
- xxxx | yyyy - Using the pipe command will match string xxxx OR yyyy
-
Combining key words with AND logic
- xxxx AND yyyy - using upper case AND command will match string xxxx AND yyyy
-
Numeric range matching
-
Example 1 - matching a single number between 0 to 9
-
[0-9]
-
-
Example 2 - Matching a 2 digit 10 to 99
- [1-9][0-9]
-
Example 1 - matching - 0 to 255
-
[0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5].
-
-
Examples of numerous number matching options
-
000..255: ^([01][0-9][0-9]|2[0-4][0-9]|25[0-5])$
-
0 or 000..255: ^([01]?[0-9]?[0-9]|2[0-4][0-9]|25[0-5])$
-
0 or 000..127: ^(0?[0-9]?[0-9]|1[01][0-9]|12[0-7])$
-
0..999: ^([0-9]|[1-9][0-9]|[1-9][0-9][0-9])$
-
000..999: ^[0-9]{3}$
-
0 or 000..999: ^[0-9]{1,3}$
-
1..999: ^([1-9]|[1-9][0-9]|[1-9][0-9][0-9])$
-
001..999: ^(00[1-9]|0[1-9][0-9]|[1-9][0-9][0-9])$
-
1 or 001..999: ^(0{0,2}[1-9]|0?[1-9][0-9]|[1-9][0-9][0-9])$
-
0 or 00..59: ^[0-5]?[0-9]$
-
0 or 000..366: ^([012]?[0-9]?[0-9]|3[0-5][0-9]|36[0-6])$
-
-
-
Case insensitive matching
Tested RegEx Expressions
The following Classification Tags and RegEx expressions have been tested using ssh prompt. They contain the necessary escape characters to work with bash prompt over ssh and can be copied and pasted to the ssh session to set up a classification rule. The data base used to test these expressions contained words in German, French, Italian, Spanish and English. German, French and Spanish languages contain accented (i.e é, ë, ê, è, ñ) and or special characters (i.e. German language ß). The following tested RegEx's do not include accommodation for accented or special characters. In a database search using these expressions data up to a accented character will be shown, the accented character and any letters following will not be displayed.
Identify Executable Files
Format: This Regular Expression will identify executable files in the format of <file name>.<File Extension>. The expression will identify the following executable file extensions:
BAT, BIN, CMD, COM, CPL, EXE, GADGET, INF1, INS, INX, ISU, JOB, JSE, LNK, MSC, MSI, MSP, MST, PAF, PIF, PS1, REG, RGS, SCR, SCT, SCT, SHB, SHS, U3P, VB, VBE, VBS, VBSCRIPT, WS, WSF, WSH, ACTION, APP, COMMAND, CSH, IPA, KSH, OSX, OUT, PRG, RUN, WORKFLOW
Identify Executable Files RegEx Expression: searchctl classification add --name 'executablefiles' --regex '(.*\.(BAT|BIN|CMD|COM|CPL|EXE|GADGET|INF1|INS|INX|ISU|JOB|JSE|LNK|MSC|MSI|MSP|MST|PAF|PIF|PS1|REG|RGS|SCR|SCT|SCT|SHB|SHS|U3P|VB|VBE|VBS|VBSCRIPT|WS|WSF|WSH|ACTION|APP|COMMAND|CSH|IPA|KSH|OSX|OUT|PRG|RUN|WORKFLOW))'
Tag: executablefiles
Key Words: Executable File
Keyword RegEx Expression: searchctl classifications add --name 'executablefilekeyword' --regex '((?i)(Executable|File|Files|Identify|Extension|Extensions))'
Phrase Example: Identify Executable File Extensions
Security: File extensions are not considered PII, PCI, PHI, or GDPR data
Files with URL's
Format: This Regular Expression can be used to find URL's in a document.
Search URL's RegEx Expression: searchctl classification add --name 'searchurl' --regex '(http|ftp|https):\/\/([\w_-]+(?:(?:\.[\w_-]+)+))([\w.,@?^=%&:\/~+#-]*[\w@?^=%&\/~+#-])'
Tag: searchurl
Key Words: Find, Search, URL, URL's
Keyword RegEx Expression: searchctl classifications add --name 'searchurlkeyword' --regex '((?i)(URL|URL's|Search|Identify|Find))'
Phrase Example: Find URL's, Identify URL
Security: URL's are not considered PII, PCI, PHI, or GDPR data
Document Security Classification
Format: string match case insensitive
Document Security Classification RegEx Expression: searchctl classifications add --name 'docclass' --regex '((?i)(Public|Private|Restricted|Confidential|Secret|Top|Unrestricted|Propritary|Sensitive|Unclassified|Tres secret defense|Secret defense|Confidentiel defense|Diffusion restreinte|STRENG GEHEIM|GEHEIM|VS-VERTRAULICH|VS-NUR FUR DEN DIENSTGEBRAUCH|Segretissimo|Segreto|Riservatissimo|Riservato|Secreto|Reservado|Confidencial|Difusion Limitada|OFFICIAL-SENSITIVE|OFFICIAL|Confidentiel|Protected|Protoge))'
Name
Format: First Last Name
Name RegEx Expression: searchctl classification add --name 'names' --regex '[a-zA-Z]+[\-'"'"'\s]?[a-zA-Z ]{1,40}'
Key Words: Name, Nombre, Nome, First Name, Last Name, Apellido, Cognome, Nom de famille, Familienname, Nachname
Name Keyword RegEx Expression: searchctl classification add --name 'nameskeyword' --regex '(Name|Nombre|Nome|First|Last|Middle|Zuerst|Letzte|Mitte|Milieu|D'"'"'abord|Durer|Primo|Prima|Medio|Media|Scorso|Scorsa|Ultimo|Ultima)'
Phrase Example: Customers Name, Patients Name, Kundenname, Nom du client,
Nome del cliente, Nombre de las clientas
Security:
Address
Street Address
Security:
North American Street Address
Format: Number followed by street name and designation i.e. 125 June Street
Street RegEx Expression: searchctl classification add --name 'nastreet' --regex '(?i)\d+(\s+\w+){1,}\s+(?:st(?:\.|reet)?|dr(?:\.|ive)?|pl(?:\.|ace)?|ave(?:\.|nue)?|rd|road|lane|ln.|drive|way|court|ct.|plaza|square|run|parkway|point|pike|square|driveway|trace|park|terrace|blvd)'
Key Words: Drive, drive, Street, street, St. Place, Lane, Ln., ln., Road, Rd., rd., Avenue, avenue, Ave., ave., Circle, Court, court, Ct., ct., Way, Plaza, Square, square, Run, run, Parway, parkway, Pkw., pkw., Point, point, Pike, pike, driveway, trace, Park, park, terrace, Terrace, blvd
North American Street Address Keyword Regex Expression: searchctl classification add --name 'nastreetkeyword' --regex '((?i)(Drive|drive|Street|street|Place|Lane|Ln.|ln.|Road|Rd.|rd.|Avenue|avenue|Ave.|ave.|Circle|Court|court|Ct.|ct.|Way|Ave|Plaza|Square|square|Run|run|Parway|parkway|Pkw.|pkw.|Point|point|Pike|pike|driveway|trace|Park|park|terrace|Terrace|blvd))'
German Street Address
Format: Street Name followed by Number i.e. Kieler Strasse 89
French Street Name RegEx Expression: searchctl classification add --name 'gstreet' --regex '([a-zA-Z]+\s*-?[a-zA-Z]+\s*-?[a-zA-Z]+\s*\d{1,3})'
Key Words: Weg, Straße, Allee, Mitte
German Street Address Keyword Regex Expression: searchctl classification add --name 'gstreetkeyword' --regex '(Weg|Strasze|Allee|Mitte)'
French Street Address
Format: Number followed by street designation (i.e. rue, quai) followed be name. i.e. 48 rue des Lacs
French Street Name RegEx Expression: searchctl classification add --name 'frstreet' --regex '((\d{1,3}),?\s\b(cours|rue|Rue|boulevard|Avenue|avenue|Quai|route)\s([a-zA-Z]{1,15})\s?([a-zA-Z]{1,15})\s?([a-zA-Z]{1,15})\s?([a-zA-Z]{1,15}))'
Key Words: cours, rue, Rue, boulevard, Avenue, avenue, Quai, route
French Street Address Keyword Regex Expression: searchctl classification add --name 'frstreetkeyword' --regex '((?i)(cours|rue|Rue|boulevard|Avenue|avenue|Quai|route))'
Italian Street Address
Format: Street designation (i.e. Via, corso) followed be name, followed by number i.e. Piazza Trieste e Trento 136
Italian Street Name RegEx Expression: searchctl classification add --name 'itstreet' --regex '(Via|Corso|Viale|Piazza|Largo) ([a-zA-Z ]+?),? (\d+)'
Key Words: Via, Corso, Viale, Piazza, Largo
Italian Street Address Keyword Regex Expression: searchctl classification add --name 'itstreetkeyword' --regex '((?i)(Via|Corso|Viale|Piazza|Largo))'
Spanish Street Address
Format: Street name, followed by number i.e. Rio Segura 47
Spanish Street Name RegEx Expression: searchctl classification add --name 'spstreet' --regex '([a-zA-Z./]+\s*[a-zA-Z]+\s*[a-zA-Z]+\s*[a-zA-Z]+\s*\d{1,3})'
Key Words: Calle
Spanish Street Address Keyword Regex Expression: searchctl classification add --name 'spstreetkeyword' --regex '(Calle|calle)'
United Kingdom Street Address
Note: UK Street Expression is the same as the North American Expression
Format: Number followed by street name and designation i.e. 92 Great Western Road
UK Street RegEx Expression: searchctl classification add --name 'ukstreet' --regex '(\d{1,5}\s(\w+)?([a-zA-Z]+)(\.)?\s?([a-zA-Z]+)\s?\-?([a-zA-Z]+)\s?(Drive|drive|Street|street|Place|Lane|Ln.|ln.|Road|Rd.|rd.|Avenue|avenue|Ave.|ave.|Circle|Court|court|Ct.|ct.|Way|Ave|Plaza|Square|square|Run|run|Parway|parkway|Pkw.|pkw.|Point|point|Pike|pike|driveway|trace|Park|park|terrace|Terrace|blvd)?)'
Key Words: Drive, drive, Street, street, St. Place, Lane, Ln., ln., Road, Rd., rd., Avenue, avenue, Ave., ave., Circle, Court, court, Ct., ct., Way, Plaza, Square, square, Run, run, Parway, parkway, Pkw., pkw., Point, point, Pike, pike, driveway, trace, Park, park, terrace, Terrace, blvd
UK Street Address Keyword Regex Expression: searchctl classification add --name 'ukstreetkeyword' --regex '((?i)(Drive|drive|Street|street|Place|Lane|Ln.|ln.|Road|Rd.|rd.|Avenue|avenue|Ave.|ave.|Circle|Court|court|Ct.|ct.|Way|Ave|Plaza|Square|square|Run|run|Parway|parkway|Pkw.|pkw.|Point|point|Pike|pike|driveway|trace|Park|park|terrace|Terrace|blvd))'
Street Address Key Words (North America, Germany, France, Italy, Spain, UK)
Key Words: Drive, drive, Street, street, St. Place, Lane, Ln., ln., Road, Rd., rd., Avenue, avenue, Ave., ave., Circle, Court, court, Ct., ct., Way, Plaza, Square, square, Run, run, Parway, parkway, Pkw., pkw., Point, point, Pike, pike, driveway, trace, Park, park, terrace, Terrace, blvd, Weg, Straße, Allee, Mitte, cours, rue, Rue, boulevard, Avenue, avenue, Quai, route, Via, Corso, Viale, Piazza, Largo, Calle, Address, Addresse, Indirizzo, Habla a, Dirección
Street Address Keyword RegEx Expression: searchctl classification add --name 'streetkeyword' --regex '((?i)(Drive|drive|Street|street|Place|Lane|Ln.|ln.|Road|Rd.|rd.|Avenue|avenue|Ave.|ave.|Circle|Court|court|Ct.|ct.|Way|Ave|Plaza|Square|square|Run|run|Parway|parkway|Pkw.|pkw.|Point|point|Pike|pike|driveway|trace|Park|park|terrace|Terrace|blvd|Weg|Strasze|Allee|Mitte|rue|Rue|cours|rue|boulevard|Quai|route|strada|Via|Corso|Viale|Piazza|Largo|Strada|Calle|calle|Address|Addresse|Indirizzo|Habla a|Direccion))'
Phrase Example: Street address, Adresse de rue, Dirección
City Name
Format: City Name
City RegEx Expression: searchctl classifications add --name 'city' --regex '(?:[A-Z][a-z.-]+[ ]?)+'
Key Words: City, Stadt, Ville, Città, Ciudad
City Name Keyword RegEx Expression: searchctl classifications add --name 'citykey' --regex '(City|Citta|Ciudad|Ville|Stadt).*$
Phrase Example: City address, Stadtadresse, Adresse de la ville, Indirizzo della città,
Dirección de la ciudad
Security: If a stand alone element no security restrictions required, only if in conjunction with name and street address the following security restrictions apply:
State, Region or Province
State, Region or Province Key Words
Key Words: State, Zustand,Province, Provincia,Region
Keyword RegEx Expression: searchctl classifications add --name 'srpkeyword' --regex '(State|Zustand|Province|Provincia|Region)'
German States
Format: 2 Letter abbreviation or name of German State
German State RegEx Expression: searchctl classifications add --name 'gstate' --regex '\b(?:BW|Baden-Wurttemberg|BY|Bavaria|Bayern|BE|Berlin|BB|Brandenburg|HB|Bremen|HH|Hamburg|HE|Hesse|Hessen|NI|Lower Saxony|MV|Mecklenburg-Vorpommern|NW|North Rhine-Westphalia|Nordrhein-Westfalen|RP|Rhineland-Palatinate|SL|Saarland|SN|Saxony|Sachsen|ST|Saxony-Anhalt|Sachsen-Anhalt|SH|Schleswig-Holstein|TH|Thuringia|Thuringen|Freistaat Bayern|Rheinland-Pfalz|Nordrhein-Westfalen|Niedersachsen|Zustand)\b'
Key Words: Zustand
State Region or Province Keyword RegEx Expression: searchctl classifications add --name 'srpkeyword' --regex '(State|Zustand|Province|Provincia|Region)'
Phrase Example: Zustand
Security: If a stand alone element no security restrictions required, only if in conjunction with name and street address the following security restrictions apply:
French Province
Format: 3 letter abbreviation or Province name.
French Province RegEx Expression: searchctl classifications add --name 'fstate' --regex '(Aquitaine|IDF|Ile-de-France|CBL|Centre|Basse-Normandie|Lorraine|Bretagne|Picardie|Languedoc-Roussillon|Rhone-Alpes|BRE|Brittany|NOR|Normandy|HDF|Hauts-de-France|Grand Est|Pays de la Loire|Centre-Val de Loire|BFC|Bourgogne-Franche-Comte|NAQ|Nouvelle-Aquitaine|ARA|Auvergne-Rhone-Alpes|OCC|Occitanie|Provence-Alpes-Cote d'"'"'Azur|COR|Corsica)\b'
Key Words: Province
Sate Region or Province Keyword RegEx Expression: searchctl classifications add --name 'srpkeyword' --regex '(State|Zustand|Province|Provincia|Region)'
Phrase Example: Province
Security: If a stand alone element no security restrictions required, only if in conjunction with name and street address the following security restrictions apply:
Italian Region or Province
Format: 2 Letter abbreviation or Region or Province Name (Note, Region is like a US State, and Province is like a US county)
Italian Region RegEx Expression: searchctl classifications add --name 'istate' --regex '\b(Provincia|ABR|Abruzzo|BAS|Basilicata|CAM|Campania|CAL|Calabria|CAM|Campania|EMI|Emilia-Romagna|FRI|Friuli-Venezia Giulia|LAZ|Lazio|LIG|Liguria|LOM|Lombardia|MAR|Marche|MOL |Molise|PIE |Piemonte|PUG |Puglia|SAR |Sardegna|SIC|Sicilia|Südtirol|TOS|Toscana|TRE|Trentino-Alto Adige|UMB|Umbria|VAL|Valle d'"'"'Aosta|VEN|Veneto|PD|Padova|VA|Varese|BS|Brescia|MI|Milano|PA|Palermo|AN|Ancona|CS|Cosenza|CN|Cuneo|VV|Vibo Valentia|FI|Firenze|OR|Oristano|TN|Trento|CH|Chieti|AP|Ascoli Piceno|VR|Verona|AT|Asti|MS|Massa|VC|Vercelli)\b'
Key Words: Provincia, Regione
State Region or Province Keyword RegEx Expression: searchctl classifications add --name 'srpkeyword' --regex '(State|Zustand|Province|Provincia|Region)'
Phrase Example: Provincia, Regione
Security: If a stand alone element no security restrictions required, only if in conjunction with name and street address the following security restrictions apply:
Spain
Format: Province Name or 1 or 2 letter abbreviation
Spanish Province RegEx Expression:searchctl classifications add --name 'spstate' --regex '\b(A Coruna|Araba|VI|Alava|Albacete|A|Alicante|Alacant|Almeria|O|Asturias|Avila|Badajoz|Balears|B|Barcelona|Bizkaia|Biscay|Burgos|Cacer|Cadiz|Cantabria|CS|Castellon|Castello|Ciudad Real|Cordoba|Cuenca|Gipuzkoa|Girona|Granada|Guadalajara|Huelva|HU|Huesca|Huca|J|Jaen|LO|La Rioja|Las Palmas|Leon|Lleida|Lugo|M|Madrid|MA|Malaga|Murcia|NA|Navarre|Nafarro|OR|Ourense|Palencia|Pontevedra|SA|Salamanca|Santa Cruz de Tenerife|Segovia|Sevilla|SE|Seville|Soria|Tarragona|Teruel|Toledo|V|Valencia|VA|Valladolid|Zamora|Zaragoza|Provincia)\b'
Key Words: Provincia
State Region or Province Keyword RegEx Expression: searchctl classifications add --name 'srpkeyword' --regex '(State|Zustand|Province|Provincia|Region)'
Phrase Example: Provincia
Security: If a stand alone element no security restrictions required, only if in conjunction with name and street address the following security restrictions apply:
UK
Format: Name
RegEx Expression: searchctl classifications add --name 'ukcountry' --regex '\b(Great Britain|England|Scotland|Wales|Northern Ireland|Western Isles)\b'
Key Words: Country or Region
State Region or Province Keyword RegEx Expression: searchctl classifications add --name 'srpkeyword' --regex '(State|Zustand|Province|Provincia|Region)'
Phrase Example: Country or Region
Security: If a stand alone element no security restrictions required, only if in conjunction with name and street address the following security restrictions apply:
Canadian Province
Format: Province Name or Abbreviation
Canadian Province RegEx Expression: searchctl classifications add --name 'caprov' --regex '\b(AB|ALB|Alta|Alberta|BC|CB|British Columbia|LB|Labrador|MB|Man|Manitoba|N[BLTSU]|Nfld|NF|Newfoundland|NWT|Northwest Territories|Nova Scotia|New Brunswick|Nunavut|ON|ONT|Ontario|PE|PEI|IPE|Prince Edward Island|QC|PC|QUE|QU|Quebec|SK|Sask|Saskatchewan|YT|Yukon|Yukon Territories)\b'
Key Words: Province
State Region or Province Keyword RegEx Expression: searchctl classifications add --name 'srpkeyword' --regex '(State|Zustand|Province|Provincia|Region)'
Phrase Example: Province
Security: If a stand alone element no security restrictions required, only if in conjunction with name and street address the following security restrictions apply:
US State
Format: State Name or Abbreviation
US State RegEx Expression: searchctl classifications add --name 'usstate' --regex '(?:Ala(?:(?:bam|sk)a)|Arizona|Arkansas|California|Colorado|Connecticut|Delaware|District of Columbia|Florida|Georgia|Hawaii|Idaho|Illinois|Indiana|Iowa|Kansas|Kentucky|Louisiana|Maine|Maryland|Massachusetts|Michigan|Minnesota|Miss(?:(?:issipp|our)i)|Montana|Nebraska|Nevada|New (?:Hampshire|Jersey|Mexico|York)|North (?:(?:Carolin|Dakot)a)|Ohio|Oklahoma|Oregon|Pennsylvania|Rhode Island|South (?:(?:Carolin|Dakot)a)|Tennessee|Texas|Utah|Vermont|Virginia|Washington|West Virginia|Wisconsin|Wyoming|A[KLRZ]|C[AOT]|D[CE]|FL|GA|HI|I[ADLN]|K[SY]|LA|M[ADEINOST]|N[CDEHJMVY]|O[HKR]|PA|RI|S[CD]|T[NX]|UT|V[AT]|W[AIVY])'
Key Words: State
State Region or Province Keyword RegEx Expression: searchctl classifications add --name 'srpkeyword' --regex '(State|Zustand|Province|Provincia|Region)'
Phrase Example: State name
Security: If a stand alone element no security restrictions required, only if in conjunction with name and street address the following security restrictions apply:
US Zip Code
Format: 5 digit code (xxxxx), or 5 plus 4 digit code (xxxxx-xxxx)
US Zip Code RegEx Expressions:
searchctl classification add --name 'zip' --regex '([0-9]{5})'
searchctl classification add --name 'zip9' --regex '([0-9]{5}-[0-9]{4})'
Key Words: Zip Code, Postal Code
US Zip Code Keyword RegEx Expression: searchctl classifications add --name 'zipkeyword' --regex '((?i)(Zip|Postal|Code))'
Phrase Example: Zip Code, Postal Code
Security: If a stand alone element no security restrictions required, only if in conjunction with name and street address the following security restrictions apply:
Telephone Number
Telephone Number Key Words
Key Words: Phone,Telephone,Number,Numero,Número,Mobile,Telefonnummer,Numéro,Telefono,Telefon,Téléphone,Teléfono,Handynummer,Poratble,Cell,Cellular,Cellulare|móvil
Telephone Number Keyword RegEx Expression: searchctl classification add --name 'phonekeyword' --regex '((?i)(Phone|Telephone|Number|Mobile|Telefonnummer|Telefono|Telefon|Telephone|Telefono|Handynummer|Poratble|Cell|Cellular|Cellulare|movil|Numero|de|telephone|portable))'
German Telephone Numbers
Formats:
6 2 2 (XXXXXX XX XX)
5 2 2 2 (XXXXX XX XX XX)
4 2 2 2 (XXXX XX XX XX)
RegEx Expression: searchctl classification add --name 'germanphone' --regex '([+][0-9]{1,3}[ .-])?([(]{1}[0-9]{1,6}[)])?([0-9 .-\/]{3,20})'
Key Words: Telefonnummer, Telephon, Handynummer
German Telephone Number Keyword RegEx Expression: searchctl classification add --name 'dephonekeyword' --regex '((?i)(Telefonnummer|Telefon|Handynummer))'
Phrase Example: Telefonnummer
Security: If a stand alone element no security restrictions required, only if in conjunction with name and street address the following security restrictions apply:
French Telephone Number
Format: XX XX XX XX
RegEx Expression: searchctl classification add --name 'frenchphone' --regex '\d{10}|\+33\d{9}|\+33\s\d{1}\s\d{2}\s\d{2}\s\d{2}\s\d{2}|\d{2}\s\d{2}\s\d{2}\s\d{2}\s\d{2}'
Key Words: Numéro de téléphone, Numéro de portable
French Telephone Number Keyword RegEx Expression: searchctl classification add --name 'frphonekeyword' --regex '((?i)(Numero|de|telephone|portable))'
Phrase Example: Numéro de téléphone, Numéro de portable
Security: If a stand alone element no security restrictions required, only if in conjunction with name and street address the following security restrictions apply:
Italian Telephone Number
Land Line
Format: XXXX XXXXXXX
RegEx Expression: searchctl classification add --name 'itphone' --regex '([0][1-9][0-9]{1,2}\s?[0-9]{6,11})'
Mobile Phone
Format:3xx xxxxxxxx or 3xxxxxxxxx
RegEx Expression: searchctl classification add --name 'itmoblephone' --regex '([3][0-9]{2}\s?[0-9]{6,7})'
Key Words: Numero di telefono, Numero di cellulare
ItalianTelephone Number Keyword RegEx Expression: searchctl classification add --name 'itphonekeyword' --regex '((?i)(Numero|telefono|de|cellulare))'
Phrase Example: Numero di telefono, Numero di cellulare
Security: If a stand alone element no security restrictions required, only if in conjunction with name and street address the following security restrictions apply:
Spanish Telephone Number
Format: XXX XXX XXX
RegEx Expression: searchctl classification add --name 'spanishphone' --regex '[6,7]\d{2}\s\d{3}\s\d{3}'
Key Words: Número de teléfono, Número de teléfono móvil
Spanish Telephone Number Keyword RegEx Expression: searchctl classification add --name 'spphonekeyword' --regex '((?i)(Numero|de|telefono|movil))'
Phrase Example: Número de teléfono
Security: If a stand alone element no security restrictions required, only if in conjunction with name and street address the following security restrictions apply:
UK Telephone Number
Format: XXX XXXX XXXX
RegEx Expression: searchctl classification add --name 'ukphone' --regex '\s*\(?(0|\+44)(\s*|-)\d{4}\)?(\s*|-)\d{3}(\s*|-)\d{3}\s*|(\s*\(?(0|\+44)(\s*|-)\d{3}\)?(\s*|-)\d{3}(\s*|-)\d{4}\s*)|(\s*\(?(0|\+44)(\s*|-)\d{2}\)?(\s*|-)\d{4}(\s*|-)\d{4}\s*)|(\s*(7|8)(\d{7}|\d{3}(\-|\s{1})\d{4})\s*)|(\s*\(?(0|\+44)(\s*|-)\d{3}\s\d{2}\)?(\s*|-)\d{4,5}\s*)'
Key Words: Telephone Number, Mobile Number, Cellular Number, Cell Number
UK Telephone Number Keyword RegEx Expression: searchctl classification add --name 'ukphonekeyword' --regex '((?i)(Telephone|Number|Mobile|Cellular|Cell))'
Phrase Example:Telephone Number, Mobile Number, Cellular Number, Cell Number
Security: If a stand alone element no security restrictions required, only if in conjunction with name and street address the following security restrictions apply:
North American Telephone Number
Format: XXX-XXX-XXXX
RegEx Expressions:
searchctl classifications add --name 'naphone' --regex '(\+\d{1,2}\s)?\(?\d{3}\)?[\s.-]\d{3}[\s.-]\d{4}'
searchctl classification add --name 'usaphone' --regex '(?:\+?1[-.]?)?\(?([0-9]{3})\)?[-.]?([0-9]{3})[-.]?([0-9]{4})'
Key Words: Telephone Number, Mobile Number, Cellular Number, Cell Number
North America Telephone Number Keyword RegEx Expression: searchctl classification add --name 'naphonekeyword' --regex '((?i)(Telephone|Number|Mobile|Cellular|Cell))'
Phrase Example:Telephone Number, Mobile Number, Cellular Number, Cell Number
Security: If a stand alone element no security restrictions required, only if in conjunction with name and street address the following security restrictions apply:
North American Fax Number
Format: XXX-XXX-XXXX
RegEx Expressions:
searchctl classification add --name 'fax' --regex '\+?\d{0,3}[- (]{0,2}?\d{3}[- )]{0,2}?\d{3}[- )]{0,2}?\d{4}?'
Key Words: Fax, Fax Number
North America Telephone Number Keyword RegEx Expression: searchctl classification add --name 'faxkeyword' --regex '((?i)(Fax|Number))'
Phrase Example:Fax, Fax Number
Security: If a stand alone element no security restrictions required, only if in conjunction with name and street address the following security restrictions apply:
Social Insurance Number
Social Insurance or Social Security Key Word
Key Words: Social Security, Pension Insurance, Rentenversicherung, SIN, Social Code, Sozialgesetzbuch (SGB), INSEE, Codice fiscale, NIE, Número de Identificación de Extranjero, DNI, Documento Nacional de Identidad, NINO, NI, No, Social Insurance, SIN, Social Security, SSN
Keyword RegEx Expression: searchctl classification add --name 'ssnkeyword' --regex '.*((?i)(Social|Insurance|Number|Security|SIN|SSN|Pension|INSEE|Numero|Securite|Sociale|Codice fiscale|DNI|Documento|Nacional|Identidad|NIE|Identificacion|Extranjero|NI|National|Rentenversicherung|Sozialgesetzbuch|Deutsche|Code|German|System|Identification|Italino|Italian)).*'
German Social Insurance Number
Format: 12 123456 A 123
RegEx Expression: searchctl classification add --name 'germansin' --regex '([0-9]{2}\s[0-9]{6}\s[a-zA-Z]\s[0-9]{3})'
Format: 12 123456 A 12 1
RegEx Expression: searchctl classification add --name 'germansin2' --regex '([0-9]{2}\s[0-9]{6}\s[a-zA-Z]\s[0-9]{2}\s[0-9])'
Format: 12 12345678 A 121
RegEx Expression: searchctl classification add --name 'germansin3' --regex '([0-9]{2}\s[0-9]{8}\s[a-zA-Z]\s[0-9]{3})'
Format: 12 12345678 A 12 1
RegEx Expression: searchctl classification add --name 'germansin4' --regex '([0-9]{2}\s[0-9]{8}\s[a-zA-Z]\s[0-9]{2}\s[0-9])'
Key Words: Social Security, Pension Insurance, Rentenversicherung, SIN, Social Code, Sozialgesetzbuch (SGB)
Social Insurance/Security Keyword RegEx Expression: searchctl classification add --name 'desinkeyword' --regex '((?i)(Social|Security|Pension|Insurance|Rentenversicherung|SIN|Social|Code|Sozialgesetzbuch|SGB))'
Phrase Examples: “German Social Security Number”, “German Social Security System (Sozialversicherung)”, Deutsche Sozialversicherungsnummer
Security:
French Social Insurance Number
Format: 1234567891234 12
RegEx Expression: searchctl classification add --name 'frenchsin' --regex '([0-9]{13}\s[0-9]{2})'
Format: 1 12 12 12345 123 12
INSEE RegEx Expression: searchctl classification add --name 'frenchsin2' --regex '([1-9]\s[0-9]{2}\s[0-9]{2}\s[0-9]{5}\s[0-9]{3}\s[0-9]{2})'
Key Words: INSEE
French INSEE Keyword RegEx Expression: searchctl classification add --name 'frsinkeyword' --regex '((?i)(NIRPP|INSEE|National|Identification|Number|numero|d'"'"'inscription|au|repertoire|de|securite|sociale))'
Phrase Examples: “National Identification Number” , “"numéro d'inscription au répertoire", "numéro de sécurité sociale"
Security:
Italian Codice Fiscale
Format: 16 characters alphanumeric code (i.e. MRT MTT86S28 F205Z)
RegEx Expression: searchctl classification add --name 'italiansin' --regex '([A-Za-z]{3}\s[A-Za-z]{3}\s[0-9|A-Z]{5}\s[0-9|A-Z]{5})'
Format: MRTMTT86S28F205Z (No spaces in number)
Codice Fiscale RegEx Expression: searchctl classifications add --name 'italiansin2' --regex '([A-Za-z]{6}[0-9lmnpqrstuvLMNPQRSTUV]{2}[abcdehlmprstABCDEHLMPRST]{1}[0-9lmnpqrstuvLMNPQRSTUV]{2}[A-Za-z]{1}[0-9lmnpqrstuvLMNPQRSTUV]{3}[A-Za-z]{1})|([0-9]{11})'
Key Words: Codice fiscale
Italian Codice Fiscale Keyword RegEx Expression: searchctl classification add --name 'itsinkeyword' --regex '((?i)(Codice|fiscale|italiano|Italian|fiscal|code))'
Phrase Examples: Italian fiscal code, Codice fiscale italiano
Security:
Spanish Social Insurance
NIE (Número de Identificación de Extranjero) for non Spanish Citizens
Format: K,L,X,Y,or Z, followed by 7 digits followed by a letter (i.e K1234567A)
NIE RegEx Expression: searchctl classification add --name 'spanishsin' --regex '((?i)([K-L]|[X-Z])\d{7}([A-Z]))'
Key Words: NIE, Número de Identificación de Extranjero
Spanish NIE Keyword RegEx Expression: searchctl classification add --name 'spsinkeyword' --regex '((?i)(NIE|Numero|de|Identificacion|Extranjero|DNI|Documento|Nacional|Identidad))'
Phrase Example: Número de Identificación de Extranjero
Security:
DNI (Documento Nacional de Identidad) for Spanish citizens
Format: The DNI format is 8 digits followed by a letter (example: 12345678A). The same number is used for one's driver's license.
There are two other classes of DNI for citizens of Spain:
-
'K' (example: K12345678A) for children under 14 who are Spanish residents.
-
'L' (example: L12345678A) for Spanish citizens who live outside Spain.
DNI RegEx Expression: searchctl classification add --name 'spanishsin2' --regex '((?i)([K-L]?)(\d{8}[A-Z]))'
Key Words: DNI, Documento Nacional de Identidad
Spanish DNI Keyword RegEx Expression: searchctl classification add --name 'spsinkeyword' --regex '((?i)(NIE|Numero|de|Identificación|Extranjero|DNI|Documento|Nacional|Identidad))'
Phrase Example: Documento Nacional de Identidad
Security:
UK NINO
Format: Two prefix letters, six digits and one suffix letter. ( i.e. QQ123456C)
NINO RegEx Expression: searchctl classification add --name 'uknino' --regex '(?!BG|GB|NK|KN|TN|NT|ZZ)[A-CEGHJ-PR-TW-Z][A-CEGHJ-NPR-TW-Z](?:\s*\d{2}){3}\s*[A-D]'
Key Words: NINO, NI, No.
UK NINO Keyword RegEx Expression: searchctl classification add --name 'ukninokeyword' --regex '((?i)(National|Insurance|number|NINO|NI|No.))'
Phrase Example: National Insurance number
Security:
Canadian Social Insurance Number
Format: 123-123-123 or 123 123 123
Social Insurance Number RegEx Expression: searchctl classification add --name 'canadiansin' --regex '(\d{3}-?\s?\d{3}-?\s?\d{3})'
Key Words: Social Insurance, SIN
Canadian Social Insurance Keyword RegEx Expression: searchctl classification add --name 'casinkeyword' --regex '((?i)(Social|Insurance|Number|SIN))'
Phrase Example: Social Insurance Number
Security:
US Social Security Number
Format: 123-12-123 or 123 12 1234
Social Security Number RegEx Expressions:
searchctl classification add --name 'usssn' --regex '(\d{3}-?\s?\d{2}-?\s?\d{4})'
searchctl classification add --name 'usassn' --regex '(?!(000|666|9))\d{3}-(?!00)\d{2}-(?!0000)\d{4}$|^(?!(000|666|9))\d{3}(?!00)\d{2}(?!0000)\d{4}'
Key Words: Social Security, SSN
US Social Security Keyword RegEx Expression: searchctl classification add --name 'usssnkeyword' --regex '((?i)(Social|Security|Number|SSN))'
Phrase Example: Social Security Number
Security:
Date of Birth
Format: m-d-yy or mm-dd-yy, or m-d-yyyy, or mm-dd-yyyy, or m/d/yy, or mm/dd/yy, or m/d/yyyy, or mm/dd/yyyy.
Date of Birth RegEx Expression: searchctl classification add --name 'dob' --regex '([0-1]?)([0-9])-?\/?[0-3]?[0-9]-?\/?\d{2,4}'
Format: m/d/yy, or mm/dd/yy, or m/d/yyyy, or mm/dd/yyyy.
Date of Birth RegEx Expression: searchctl classification add --name 'dob2' --regex '([0-1]?)([0-9])\/[0-3]?[0-9]\/\d{2,4}'
Format: m-d-yy or mm-dd-yy, or m-d-yyyy, or mm-dd-yyyy, .
Date of Birth RegEx Expression: searchctl classification add --name 'dob3' --regex '([0-1]?)([0-9])-[0-3]?[0-9]-\d{2,4}'
Format: mm/dd/yyyy, or mm-dd-yyyy, or mm.dd.yyyy, or m/d/yyyy, or m-d-yyyy or m.d.yyyy
Date of Birth Expression: searchctl classification add --name 'usadob' --regex '(?:(?:(?:0?[13578]|1[02])(\/|-|\.)31)\1|(?:(?:0?[1,3-9]|1[0-2])(\/|-|\.)(?:29|30)\2))(?:(?:1[6-9]|[2-9]\d)?\d{2})$|^(?:0?2(\/|-|\.)29\3(?:(?:(?:1[6-9]|[2-9]\d)?(?:0[48]|[2468][048]|[13579][26])|(?:(?:16|[2468][048]|[3579][26])00))))$|^(?:(?:0?[1-9])|(?:1[0-2]))(\/|-|\.)(?:0?[1-9]|1\d|2[0-8])\4(?:(?:1[6-9]|[2-9]\d)?\d{2})'
Key Words: DOB, Date, Data, Fecha, Birth, Geburt, naissance, nascita, nacimiento
DOB Keyword RegEx Expression: searchctl classification add --name 'dobkeyword' --regex '((?i)(Date|Birth|DOB|Geburtsdatum|Naissance|Nascita|Fecha|Nacimiento|Geburt|Data))'
Phrase Example: Date of Birth, Geburtsdatum, Date de naissance, Data di nascita, Fecha de nacimiento
Security: As a stand alone data element it is Public Data and not restricted, but with Social Security Number and Name it is restricted data.
Email RegEx Expressions:
searchctl classifications add --name 'email' --regex '[\w-\.]+@([\w-]+\.)+[\w-]{2,4}'
searchctl classification add --name 'usaemail' --regex '([a-zA-Z0-9_\-\.]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})'
Key Words: Email
Email Key Word RegEx Expression: searchctl classifications add --name 'emailkeyword' --regex '((?i)(Email|E-mail|Address|Adresse|Correo|electronico|Indirizzo\\e-mail|correo|Direccion|email))'
Key Phrase: Email, E-mail, Email Address, Correo electrónico, E-Mail-Addresse, Adresse e-mail, Indirizzo email, Dirección de correo electrónico
Security:
IBAN: Europe Only
Note IBAN is used in Europe, not Canada or US. The first two digits are for the country code (i.e "DE" for Germany) followed by a check digit comprising two characters and the national account number BBAN (basic bank account number), which is made up of the eight-digit bank sort code and the ten-digit account number
Germany, Italy, France, Spain, UK (all formats)
RegEx Expression: searchctl classifications add --name 'iban' --regex '(?:DE)\d{20}|(?:FR)\d{19}[A-Z]\d{5}|(IT)\d{2}[A-Z]\d{22}|(?:ES)\d{22}|(?:GB)\d{2}[A-Z]{4}\d{14}|(?:DE)\d{2}\s\d{4}\s\d{4}\s\d{4}\s\d{4}\s\d{2}|(?:FR)\d{2}\s\d{4}\s\d{4}\s\d{4}\s\d{4}\s\d{1}[A-Z]\d{2}\s\d{3}|(IT)\d{2}\s[A-Z]\d{3}\s\d{4}\s\d{4}\s\d{4}\s\d{4}\s\d{3}|(?:GB)\d{2}\s[A-Z]{4}\s\d{4}\s\d{4}\s\d{4}\s\d{2}|(?:ES)\d{2}\s\d{4}\s\d{4}\s\d{4}\s\d{4}\s\d{4}'
Note the following Key Words and Keyword Regex Expression apply to the Bank Acounts for Germany, France, Italy Spain and the UK:
Key Words: IBAN, BBAN, Bank Konto, Kontonummer, Bank, Numéro, compte, bancaire, Numero, conto, bancario, Número, cuenta, bancaria, Bank, Account, Number, Intrenational, IBAN
IBAN Keyword RegEx Expression: searchctl classifications add --name 'ibankeyword' --regex '((?i)(Bank|Account|Number|Numero|Nummer|Routing|Transit|Bankario|Financial|Institution|German|French|Italian|Spanish|Kontonummer|Compte|Bancaire|Conto|International|Basic|Cuenta|Banco|Konto|Bankaire|Internacional|Internazionale|Internationale|BANK|ACCOUNT|NUMBER|NUMERO|CUENTA|BANCARIA|IBAN|BBAN))'
Phrase Examples: International Bank Account Number, Basic Bank Account Number, Numero de cuenta de Banco Internacional, Numero di conto bancario internazionale, Numéro de compte bancaire international, Internationale Kontonummer
Security:
Bank Account Numbers
Germany
Format: DE29 1349 3022 4806 3708 88
German Bank Account RegEx Expression: searchctl classifications add --name 'ibande' --regex '(?:DE)\d{2}\s\d{4}\s\d{4}\s\d{4}\s\d{4}\s\d{2}'
Format: DE12345678901234567890
German Bank Account RegEx Expression: searchctl classifications add --name 'ibande2' --regex '(?:DE)\d{20}'
Key Words: Bank Konto
German IBAN Keyword RegEx Expression: searchctl classifications add --name 'debakeyword' --regex '((?i)(Kontonummer|Bank|Konto|konto|IBAN))'
Phrase Examples: Kontonummer, Bank Konto
Security:
France
Format: FR29 9169 9073 6047 1767 2P38 290
French Bank Account RegEx Expression: searchctl classifications add --name 'ibanfr' --regex '(?:FR)\d{2}\s\d{4}\s\d{4}\s\d{4}\s\d{4}\s\d{1}[A-Z]\d{2}\s\d{3}'
Format: FR1234567895487613478A12345
French Bank Account RegEx Expression: searchctl classifications add --name 'ibanfr2' --regex '(?:FR)\d{19}[A-Z]\d{5}'
Key Words: Numéro de compte bancaire
French IBAN Keyword RegEx Expression: searchctl classifications add --name 'frbakeyword' --regex '((?i)(Numero|compte|bancaire|INUMERO|DE|COMPTE|BANCAIRE|IBAN))'
Phrase Examples: Numéro de compte bancaire, Compte bancaire
Security:
Italy
Format: IT89 R374 3328 2256 2103 0440 500
Italian Bank Account RegEx Expression: searchctl classifications add --name 'ibandit' --regex '(?:IT)\d{2}\s[A-Z]\d{3}\s\d{4}\s\d{4}\s\d{4}\s\d{4}\s\d{3}'
Format: IT12A1234567891234567891234
Italian Bank Account RegEx Expression: searchctl classifications add --name 'ibandit2' --regex '(IT)\d{2}[A-Z]\d{22}'
Key Words: Numero di conto bancario
Italian IBAN Keyword RegEx Expression: searchctl classifications add --name 'itbakeyword' --regex '((?i)(Numero|conto|bancario|di|DI|NUMERO|DI|CONTO|BANCARIO|IBAN))'
Phrase Examples: Numero di conto bancario, Conto bancario
Security:
Spain
Format: ES00 4514 6356 8256 8068 7871
RegEx Expression: searchctl classifications add --name 'ibanesp' --regex '(?:ES)\d{2}\s\d{4}\s\d{4}\s\d{4}\s\d{4}\s\d{4}'
Format: ES1234567901234567890123
RegEx Expression: searchctl classifications add --name 'ibanes2' --regex '(?:ES)\d{22}'
Key Words: Número de cuenta bancaria
Spanish IBAN Keyword RegEx Expression: searchctl classifications add --name 'spbakeyword' --regex '((?i)(Numero|cuenta|bancaria|de|DE|NUMERO|CUENTA|BANCARIA|IBAN))'
Phrase Examples: Número de cuenta bancaria, Cuenta bancaria
Security:
United Kingdom
Format: GB96 CZTD 5452 0531 6999 91
RegEx Expression: searchctl classifications add --name 'ibanduk' --regex '(?:GB)\d{2}\s[A-Z]{4}\s\d{4}\s\d{4}\s\d{4}\s\d{2}'
Format: GB12ABCD12345678912345
RegEx Expression: searchctl classifications add --name 'ibanduk2' --regex '(?:GB)\d{2}[A-Z]{4}\d{14}'
Key Words: Bank, Account, Number, Intrenational, IBAN
UK IBAN Keyword RegEx Expression: searchctl classifications add --name 'ukbakeyword' --regex '((?i)(Bank|Account|Number|Intrenational|BANK|ACCOUNT|NUMBER|IBAN))'
Phrase Examples: International Bank Account Number, IBAN Number
Security:
Bank Account Numbers: Canada and US only
Account Numbers Canada and US
Canadian Account Numbers breakdown:
Financial Institution 3 digits
Bank Transit Number 5 digits
Account Number 7 - 12 digits
Total 15 -20 digits
US Account Numbers Breakdown:
US Routing Number 9 digits
Account Number 10 - 12 digits
Total 19 - 21 Digits
Bank Account Number US (10 - 12 digits) and Canada (7- 12 digits)
US
Format: 10 to 12 digits
US Bank Account RegEx Expression: searchctl classifications add --name 'usba' --regex '(\d{10,12})'
Key Words: Bank Account Number
Keyword RegEx Expression: searchctl classifications add --name 'nabakeyword' --regex '((?i)(Bank|Account|Number|BANK|ACCOUNT|NUMBER|Routing|ROUTING|Transit|Financial|Institution|Canadian|Canada|US))'
Phrase Examples: Bank Account, Bank Account Number
Security:
Canada
Format: 7 to 12 digits
Canadian Bank Account RegEx Expression: searchctl classifications add --name 'caba' --regex '(\d{7,12})'
Key Words: Canadian Bank Account Number
Keyword RegEx Expression: searchctl classifications add --name 'cabakeyword' --regex '((?i)(Bank|Account|Number|BANK|ACCOUNT|NUMBER|Routing|Transit|Financial|Institution|Canadian|Canada))'
Phrase Examples: Bank Account, Bank Account Number
Security:
Bank Routing Numbers
US Routing Number
Format: Nine Digit Bank Routing Transit Number complying with ABA Rules:
US Routing Number RegEx Expression: searchctl classifications add --name 'usbr' --regex '((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})'
Key Words: Bank Routing Number
Keyword RegEx Expression: searchctl classifications add --name 'usbrkeyword' --regex '((?i)(Bank|Account|Number||BANK|ACCOUNT|NUMBER|ROUTING|Routing|Transit|Financial|Institution|US))'
Phrase Examples: US Bank Routing Number
Security: Public information
Canadian Routing Numbers
Canadian Routing numbers are composed of a 5 digit Bank Transit Number and a 3 digit Financial Institution number.
Canadian Routing Number RegEx Expression: searchctl classifications add --name 'cabr' --regex '(\d{5}-?\s?\d{3})'
Key Words: Routing Number, Financial Institution, Transit Number
Keyword RegEx Expression: searchctl classifications add --name 'cabrkeyword' --regex '((?i)(Bank|Account|Number||BANK|ACCOUNT|NUMBER|ROUTING|Routing|Transit|Financial|Institution|Canadian|Canada))'
Phrase Examples: Canadian Bank Routing Number, Financial Institution, Bank Transit Number
Security: Public information
Routing and Bank Account Numbers
US
Format: Nine Digit Bank Routing Transit Number plus 10 to 12 digit Bank Account Number
US Routing plus Bank Account RegEx Expression: searchctl classifications add --name 'usbrba' --regex '(((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7}))-?\s?(\d{10,12})'
Key Words: Bank Account Number
Keyword RegEx Expression: searchctl classifications add --name 'usbrbakeyword' --regex '((?i)(Bank|Account|Number||BANK|ACCOUNT|NUMBER|ROUTING|Routing|Transit|Financial|Institution|US))'
Phrase Examples: Bank Account Data
Security:
Canada
Format: 5 digit Bank Transit Number, a 3 digit Financial Institution number and 7 to 12 digit Account Number
Canadian Routing plus Bank Account RegEx Expression: searchctl classifications add --name 'carba' --regex '(\d{5}-?\s?\d{3}-?\s?\d{7,12})'
Key Words: Bank Account Number
Keyword RegEx Expression: searchctl classifications add --name 'carbakeyword' --regex '((?i)(Bank|Account|Number||BANK|ACCOUNT|NUMBER|ROUTING|Routing|Transit|Financial|Institution|Canadian|Canada))'
Phrase Examples: Bank Account Data
Security:
Credit Card Number
Regex Expression for Visa (Vpay), Visa Electron, AMX, MasterCard, Maestro, Diners Club Cart Blanche, Diners Club International, Diners Club US & Canada, Discover to match Length, IIN Ranges and Spacing Patterns shown in Credit Card IIN Ranges & Spacing Patterns:
searchctl classifications add --name 'creditcard' --regex '((2[2-7]\d{2}-?\s?\d{4}-?\s?\d{4}-?\s?\d{4})|(4\d{3}-?\s?\d{4}-?\s?\d{4}-?\s?\d{4})|(3[0-9]\d{2}-?\s?\d{6}-?\s?\d{4,5})|(5[0-8]\d{2}-?\s?\d{4,6}-?\s?\d{4,5}-?\s?\d{0,4}-?\s?\d{0,3})|(6[0-9]\d{2}-?\s?\d{4,6}-?\s?\d{4,5}-?\s?\d{0,4})-?\s?\d{0,3})'
Key Words: Credit Card, CCN
Keyword RegEx Expression: searchctl classifications add --name 'creditcardkeyword' --regex '((?i)(Credit|Card|Number|Master|Discover|American Express|Maestro|Visa|CC|Diners Club|International|Cart Blanche|Electron|AMX|Kreditkartennummer|Numero|Carte|credito|de|carta|tarjeta))'
Phrase Example: Credit Card Number, Kreditkartennummer, Numéro de Carte de Crédit, Numero di carta di credito, Número de tarjeta de crédito, Mastercard, VISA, Discover Card, American Express, AMX, Maestro, Cart Blanche, Diners Club, Diners Club International
Security:
ACH Format Compliance Check
Automated Clearing House (ACH) is an electronic network for financial transactions. These transactions include credit and debit transactions. ACH credit transfers include direct deposit payroll and vendor payments.Can use the following RegEx to pattern match numbers to check ACH format compliance, check for 1 to 17 alpha-numerics:
ACH Format Compliance Check Regex Expression: searchctl classifications add --name 'achcompliance' --regex '\w{1,17}'
Key Words: ACH, ACH Check
Keyword RegEx Expression: searchctl classifications add --name 'achkeyword' --regex '(ACH|Compliance|Check)'
Phrase Examples: ACH Compliance
Security:
Credit Card CVV
Format: xx, or xxx, or xxxx
Credit Card CVV RegEx Expression (2 to 4 Digit): searchctl classifications add --name 'cvv' --regex '\d{2,4}'
Format: xxx
Credit Card CVV RegEx Expression (3 Digit): searchctl classifications add --name 'cvv3' --regex '\d{3}'
Key Words: CVV, CVC
Keyword RegEx Expression: searchctl classifications add --name 'cvvkeyword' --regex '((?i)(CVV|CVC|Card|Karten|Verification|Number|Code|Verificacion|Verifiziernummer|Uberprufung|Verifica|Wert|Valeur|Valore|Valor|Le code de|Codigo|Codice|Numero|Nombre|Nummer))'
Phrase Example: Card Verification Value, Card Verification Code, Credit Card Verification, CVV Number, CVC Number, Credit Verification Value Number, Credit Card Verification Number, Karten Verifiziernummer, Valeur de vérification de la carte, Valore di verifica della carta, valor de verificación de la tarjeta, Kartenbestätigungscode, Le code de vérification de carte, Codice di verifica della carta, Código de verificación de la tarjeta
Security: As a stand alone data element there are no restrictions but, In conjunction with Credit Card Number and Expiration Date the following restrictions apply
Expiration Date
Format: mm/yy
Expiration Data RegEx: searchctl classifications add --name 'exp2' --regex '(?:0[1-9]|1[0-2])\/[0-9]{2}'
Format: mm/yy or mm/yyyy
Expiration Data RegEx: searchctl classifications add --name 'exp2or4' --regex '(?:0[1-9]|1[0-2])\/[0-9]{2,4}'
Key Words: Expiration Date, Haltbarkeitsdatum, Ablaufdatum der Kreditkarte, Date d'expiration, Data di scadenza, Fecha de caducidad
Keyword RegEx Expression: searchctl classifications add --name 'ccexpkeyword' --regex '((?i)(Credit|Card|Expiration|Date|Data|Fecha|Haltbarkeitsdatum|Ablaufdatum|Kreditkarte|scadenza|caducidad|Credito|Anerkennung|Credito|Tarjeta|Carta|Carte|Karte))'
Phrase Examples: Credit Card Expiration, Credit Card Expiration Date, Ablaufdatum der Kreditkarte, Date d'expiration de la carte de crédit, Data di scadenza della carta di credito, Fecha de vencimiento de la tarjeta de crédito
Security: As a stand alone data element there are no restrictions but, In conjunction with Credit Card Number and CVV the following restrictions apply.
Medical Data
Medical Record Number (MRN)
Format: xxx-x-xxxxx, or xxx x xxxxx, or xxxxxxxxx
Medical Record RegEx Expression: searchctl classifications add --name 'mrn' --regex '[0-9]{3}-?\s?[0-9]{1}-?\s?[0-9]{5}'
Format: 05xxxxxxx
Medical Record RegEx Expression: searchctl classification add --name 'usamrn' --regex '(05)\d{7}'
Key Words: MRN, Medical Record Number, Nummer der Krankenakte, Numéro de dossier médical, Numero di cartella clinica, Numero de historia clinica
Keyword RegEx Expression: searchctl classifications add --name 'mrnkeyword' --regex '((?i)(Medical|Record|Number|MRN|Nummer|Krankenakte|Numero|dossier|medical|cartella|clinica|historia|clinica|Geduldig|Patiente|Patient|Paziente|Paciente|Med Rec))'
Phrase Example: Patients Medical Record Number, Nummer der Patientenakte, Numéro de dossier médical du patient, Numero di cartella clinica del paziente, Número de historia clínica del paciente
Security:
National Provider Identifier (NPI)
Format: 10 digits XXXXXXXXXX
RegEx Expression: searchctl classification add --name 'npi' --regex '\d{10}'
Key Words: NPI,"National Provider Identifier"
Keyword RegEx Expression: searchctl classifications add --name 'npikeyword' --regex '((?i)(NPI|National|Provider|Identifier|ID))'
Phrase Example: NPI,"National Provider Identifier"
Security:
Financial Identification Number (FIN)
Format: 1200xxxxxx
RegEx Expression: searchctl classification add --name 'fin' --regex '(1200)\d{6}'
Key Words: FIN,"Financial Identification Number","Financial ID","Patient ID","Encounter ID","Encounter #"
Keyword RegEx Expression: searchctl classifications add --name 'finkeyword' --regex '((?i)(FIN|Financial|Identification|Number|ID|Patient|Encounter))'
Phrase Example: FIN,"Financial Identification Number","Financial ID","Patient ID","Encounter ID","Encounter #"
Security:
Medical License Number
Format: 2 letter prefix followed by 5 digits (i.e. ME.10003)
RegEx Expression: searchctl classification add --name 'mln' --regex '[A-Z]{2}\.\d{5}'
Key Words: License,"License #","Medical License Number"
Keyword RegEx Expression: searchctl classifications add --name 'mlnkeyword' --regex '((?i)(License|Medical|Number|MLN))'
Phrase Example: FIN,"Financial Identification Number","Financial ID","Patient ID","Encounter ID","Encounter #"
Security:
J Number
Format: J ollowed by 8 digits (Jxxxxxxxx)
RegEx Expression: searchctl classification add --name 'jnumber' --regex '[Jj][0-9]{8}''
Key Words: "J #","J Number"
Keyword RegEx Expression: searchctl classifications add --name 'Jkeyword' --regex '((?i)(J|Number))'
Phrase Example: "J #","J Number"
Security:
DEA Registration Number
Format: 2 letter prefix followed by 7 digits (i.e. MR0622476)
RegEx Expression: searchctl classification add --name 'dea' --regex '[A-HJ-NPR-UX]{1}[A-Z]{1}\d{7}'
Key Words: DEA,"DEA Registration","Drug Enforcement Administration"
Keyword RegEx Expression: searchctl classifications add --name 'deakeyword' --regex '((?i)(DEA|Registration|Drug|Enforcement|Administration|Number))'
Phrase Example: DEA,"DEA Registration","Drug Enforcement Administration"
Security:
Blood Type
Format: X(+/-)
Blood Type RegEx Expression: searchctl classifications add --name 'bloodtype' --regex '(A|B|AB|O)[+-]'
Key Words: Blood Type
Keyword RegEx Expression: searchctl classifications add --name 'btkeyword' --regex '((?i)(Blood Type|Blutgruppe|Groupe sanguin|Gruppo sanguigno|Tipo de sangre))'
Phrase Example: Blood Type, Blutgruppe, Groupe sanguin, Gruppo sanguigno, Tipo de sangre
Security:
Weight
Metric or English:
Weight RegEx Expression: searchctl classification add --name 'weight' --regex '(\d*\.?\d+)\s*(pounds?|lbs?|lb?|kgs?|kg)'
Key Words: Weight
Keyword RegEx Expression: searchctl classifications add --name 'weightkeyword' --regex '((?i)(Weight|Gewicht|Poids|Peso))'
Phrase Example: Weight, Gewicht, Poids, Peso,
Security:
Height
Format: cm or ft, in or ‘ “.
RegEx Expression: searchctl classification add --name 'height' --regex '(\d{1,3}\s?(ft)\s?\d{1,2}\s?(in)?)|(\d*\.?\d*\scm)'
Format: cm
RegEx Expression: searchctl classification add --name 'heightm' --regex '(\d*\.?\d*\scm)'
Format: ft, in or ', "
RegEx Expression: searchctl classification add --name 'heighti' --regex '(\d{1,3}'"'"'?\s?(ft)?\s?\d{1,2}\"?\s?(in)?)'
Note: For English height data, the characters ‘ and “ are format sensitive. For example
5'9" worked
while
5’6” did not work
Key Words: Height
Keyword RegEx Expression: searchctl classifications add --name 'heightkeyword' --regex '((?i)(Height|Hohe|Hohe|la taille|Taille|Altezza|Altura))'
Phrase Example: Height, Höhe, la taille, Altezza, Altura
Security:
US State Drivers License Numbers
Drivers License Key Word
Key Words: Driver, Drivers, Driver's License, Licenses
Keyword RegEx Expression: searchctl classification add --name 'dlkeywords' --regex '((?i)(Drivers|Driver'"'"'s|Driver|Licenses|License|Numbers|Number))'
Phrase Example: "Drivers License Number"
Alabama
Format: Alabama driver's license numbers are seven numbers, unformated. For example: 6996164.
RegEx Expression: searchctl classification add --name 'Alabamadl' --regex '\d{7}'
Security:
Alaska
Format: Alaska driver's license numbers are seven numbers, unformated. For example: 6244114..
RegEx Expression: searchctl classification add --name 'Alaskadl' --regex '\d{7}'
Security:
Arizona
Format: Arizona driver's license numbers consist of one letter and eight numbers. For example: B13654424.
RegEx Expression : searchctl classification add --name 'Arizonadl' --regex '[a-zA-Z]\d{8}'
Format: Arizona driver's license numbers may also consist of nine numbers, unformated. For example: 113654424.
RegEx Expression : searchctl classification add --name 'Arizonadl2' --regex '\d{9}'
Security:
California
Format: California driver's license numbers consist of one letter and seven numbers. For example: A0002144.
RegEx Expression: searchctl classification add --name 'Californiadl' --regex '[a-zA-Z]\d{7}'
Security:
Colorado
Format: Colorado driver's license numbers are nine numbers formatted as ##-###-####. For example: 94-33-0101.
RegEx Expression: searchctl classification add --name 'Coloradodl' --regex '\d{2}-\d{3}-\d{4}'
Security:
Connecticut
Format: Connecticut driver's license numbers are nine numbers, unformated. For example: 146825129.
RegEx Expression: searchctl classification add --name 'Connecticutdl' --regex '\d{9}'
Security:
Delaware
Format: Delaware driver's license numbers are a seven numbers, unformated. For example:1232805.
RegEx Expression: searchctl classification add --name 'Delawaredl' --regex '\d{7}'
Security:
Florida
Format: Florida driver's license numbers consist of one letter and 12 numbers, using the format L##-###-##-###-#. For example: G544-061-73-925-0.
RegEx Expression: searchctl classification add --name 'Floridadl' --regex '[a-zA-Z]\d{3}-\d{3}-\d{2}-\d{3}-\d{1}'
Format: Florida driver's license numbers may also consist of one letter and 12 numbers, unformatted. For example: G544061739250.
RegEx Expression: searchctl classification add --name 'Floridadl2' --regex '[a-zA-Z]\d{12}'
Security:
Georgia
Format: Georgia driver's license numbers are nine numbers, unformated. For example: 199999999.
RegEx Expression: searchctl classification add --name 'Georgiadl' --regex '\d{9}'
Security:
Hawaii
Format: Hawaii driver's license numbers consist of one letter and eight numbers, unformated. For example: H00000002.
RegEx Expression: searchctl classification add --name 'Hawaiidl' --regex '[a-zA-Z]\d{8}'
Security:
Idaho
Format: Idaho driver's license numbers consist of two letters, six numbers, and one letter. For example: AA123456Z.
RegEx Expression: searchctl classification add --name 'Idahodl' --regex '[a-zA-Z]{2}\d{6}[a-zA-Z]'
Security:
Illinois
Format: Illinois driver's license numbers consist of one letter and 11 numbers formatted as L###-####-####. For example: D400-7836-0001.
RegEx Expression: searchctl classification add --name 'IIllinoisdl' --regex '[a-zA-Z]\d{3}-\d{4}-\d{4}'
Format: Illinois driver's license numbers may also consist of one letter and 11 numbers formatted as L###########. For example: D40078360001..
RegEx Expression: searchctl classification add --name 'IIllinoisdl2' --regex '[a-zA-Z]\d{11}'
Security:
Indiana
Format: Indiana driver's license numbers consist of 10 numbers formatted as ####-##-####. For example: 0299-11-6078.
RegEx Expression: searchctl classification add --name 'Indianadl' --regex '\d{4}-\d{2}-\d{4}'
Security:
Iowa
Format: Iowa driver's license numbers consist of three numbers, two letters, and four numbers. For example: 123AB9755.
RegEx Expression: searchctl classification add --name 'Iowadl' --regex '\d{3}[a-zA-Z]{2}\d{4}'
Format: Iowa driver's license numbers may also consist of nine numbers, unformated. For example: 123456789.
RegEx Expression: searchctl classification add --name 'Iowa9dl' --regex '\d{9}'
Security:
Kansas
Format: Kansas driver's license numbers consist of one letter and eight numbers formatted as L##-##-####. For example: K00-09-7443.
RegEx Expression: searchctl classification add --name 'Kansasdl' --regex '[a-zA-Z]\d{2}-\d{2}-\d{4}'
Security:
Kentucky
Format: Kentucky driver's license numbers consist of one letter and eight numbers formatted as L##-###-###. For example: V12-345-678.
RegEx Expression: searchctl classification add --name 'Kentuckydl' --regex '[a-zA-Z]\d{2}-\d{3}-\d{3}'
Security:
Louisiana
Format: Louisiana driver's license numbers are a nine numbers, unformated. For example: 123456789.
RegEx Expression: searchctl classification add --name 'Louisianadl' --regex '\d{9}'
Security:
Maine
Format: Maine driver's license numbers are seven numbers, unformated. For example: 1234567.
RegEx Expression: searchctl classification add --name 'Mainedl' --regex '\d{7}'
Security:
Maryland
Format: Maryland driver's license numbers consist of one letter and 12 numbers formatted as L-###-###-###-###. For example: S-514-778-616-977.
RegEx Expression: searchctl classification add --name 'Marylanddl' --regex '[a-zA-Z]-\d{3}-\d{3}-\d{3}-\d{3}'
Format: Maryland driver's license numbers may also consist of one letter and 12 numbers, unformatted. For example: S514778616977.
RegEx Expression: searchctl classification add --name 'Marylandd2l' --regex '[a-zA-Z]\d{12}'
Security:
Massachusetts
Format: Massachusetts driver's license numbers consist of one letter and nine numbers. For example: S99988881.
RegEx Expression: searchctl classification add --name 'Massachusettsdl' --regex '[a-zA-Z]\d{8}'
Security:
Michigan
Format: Michigan driver's license numbers consist of one letter and 12 numbers formatted as L ### ### ### ###. For example: P 800 000 224 312.
RegEx Expression: searchctl classification add --name 'Michigandl' --regex '[a-zA-Z]\s\d{3}\s\d{3}\s\d{3}\s\d{3}'
Format: Michigan driver's license numbers may also be one letter and 12 numbers, unformatted. For example: P800000224322.
RegEx Expression: searchctl classification add --name 'Michigandl2' --regex '[a-zA-Z]\d{12}'
Security:
Minnesota
Format: Minnesota drivers license consist of one letter and 12 numbers formatted as L-###-###-###-###. For example: S514-778-616-977.
RegEx Expression: searchctl classification add --name 'Minnesotadl' --regex '[a-zA-Z]\d{3}-\d{3}-\d{3}-\d{3}'
Format: Minnesota driver's license numbers may also consist of one letter and 12 numbers, unformatted. For example: S514778616977.
RegEx Expression: searchctl classification add --name 'Minnesotadl2' --regex '[a-zA-Z]\d{12}'
Security:
Mississipi
Format: Mississippi driver's license numbers are nine numbers formatted like a Social Security number as ###-##-####. For example: 125-01-2050.
RegEx Expression: searchctl classification add --name 'Mississippidl' --regex '\d{3}-\d{2}-\d{4}'
Format: Mississippi driver's license numbers may may also consist of nine numbers, unformated. For example: 125012050.
RegEx Expression: searchctl classification add --name 'Mississippidl2' --regex '\d{9}'
Security:
Missouri
Format: Missouri driver's license numbers consist of one letter and nine numbers, unformated. For example: F050256006.
RegEx Expression: searchctl classification add --name 'Missouridl' --regex '[a-zA-Z]\d{9}'
Security:
Montana
Format: Montana driver's license numbers are 13 numbers: first 2 - month of biirth, next 3 random, next 4 - year of birth, next number is 41, last 2 - day of birth. For example: 0898719684104.
RegEx Expression: searchctl classification add --name 'Montanadl' --regex '(([0][1-9]|[1][0-2])\d{3}([1-9][0-9]{3})41([0][1-9]|[1][0-9]|[3][0-1]))'
Format: Prior licenses used either the licensee’s Social Security number or the Social Security number followed by four zeros. For example: 2623806260000.
RegEx Expression: searchctl classification add --name 'Montanadl2' --regex '\d{9,13}'
Security:
Nebraska
Format: Nebraska driver's license numbers consist of one letter and eight numbers, unformated. For example: A20600249.
RegEx Expression: searchctl classification add --name 'Nebraskadl' --regex '[a-zA-Z]\d{8}'
Security:
Navada
Format: Nevada driver's license numbers consist of 12 numbers, unformated. For example: 0002102201.
RegEx Expression: searchctl classification add --name 'Nevadadl' --regex '\d{12}'
Format: Older Nevada driver's license numbers consist of 9 to 10 numbers, unformated. For example: 626926253.
RegEx Expression: searchctl classification add --name 'Nevadadl2' --regex '\d{9,10}'
Security:
New Hampshire
Format: The upgraded system now issues New Hampshire driver licenses with three letters and eight randomly assigned digits for a total of 11 characters. For example: NHL12506717.
RegEx Expression: searchctl classification add --name 'NewHampshiredl' --regex '[a-zA-Z]{3}\d{8}'
Format: Older New Hampshire driver's license numbers are 10 numbers: First 2 digits - month of birth, next 3 - the first and last letters of last name and the first initial of first name, next 4 - year and date of birth, last random digit. For example: 06HYD46018.
RegEx Expression: searchctl classification add --name 'NewHampshiredl2' --regex '([0][1-9]|[1][0-2])[a-zA-Z]{3}\d{2}(0[1-9]|[1-2][0-9]|3[0-1])\d'
Security:
New Jersey
Format: New Jersey driver's license numbers consist of one letter and 14 numbers formatted as L####-#####-#####. The first character is the first initial of the last name, next 9 digits are assigned, last 5 digits = the month and year of birth and a code for eye color . For example: A5438 07571 07894.
RegEx Expression: searchctl classification add --name 'NewJerseydl' --regex '[a-zA-Z]\d{4}\s\d{5}\s\d{5}'
Format: New Jersey driver's lecense numbers may also consist of one letter followed by 14 digits with no spaces. For example: A54380757107894.
RegEx Expression: searchctl classification add --name 'NewJerseydl2' --regex '[a-zA-Z]\d{14}'
Security:
New Mexico
Format: New Mexico driver's license numbers are nine numbers, unformated. For example: 113696424.
RegEx Expression: searchctl classification add --name 'NewMexicodl' --regex '\d{9}'
Security:
New York
Format: New York driver's license numbers are nine numbers formatted as ### ### ###. For example: 123 456 789..
RegEx Expression: searchctl classification add --name 'NewYorkdl' --regex '\d{3} \d{3} \d{3}'
Format: New York driver's license numbers may also consist of nine numbers with no spaces. For example: 123456789.
RegEx Expression: searchctl classification add --name 'NewYorkdl2' --regex '\d{9}'
Security:
North Carolina
Format: North Carolina driver's license numbers are 12 numbers, unformated. For example: 300031499905.
RegEx Expression: searchctl classification add --name 'NorthCarolinadl' --regex '\d{12}'
Security:
North Dakota
Format: North Dakota driver's license numbers are 3 letters and 6 numbers: first 3 letters of last name, next 2 year of birth, finally 4 digits. For example: HAG-46-7689.
RegEx Expression: searchctl classification add --name 'NorthDakotadl' --regex '[a-zA-Z]{3}-\d{2}-\d{4}'
Security:
Ohio
Format: Ohio driver's license numbers are two letters and six numbers. For example: TL545796.
RegEx Expression: searchctl classification add --name 'Ohiodl' --regex '[a-zA-Z]{2}[0-9]{6}'
Security:
Oklahoma
Format: Oklahoma driver's license numbers consist of one letter and nine numbers,unformated. For example: B000062835 .
RegEx Expression: searchctl classification add --name 'Oklahomadl' --regex '[a-zA-Z]\d{9}'
Security:
Oregon
Format: Oregon driver's license numbers are a seven numbers, unformated. For example: 6110033.
RegEx Expression: searchctl classification add --name 'Oregondl' --regex '\d{7}'
Security:
Pennsylvania
Format: Pennsylvania driver's license numbers are eight numbers formatted as ## ### ###. For example: 99 900 104..
RegEx Expression: searchctl classification add --name 'Pennsylvaniadl' --regex '\d{2}\s\d{3}\s\d{3}'
Security:
Rhode Island
Format: Rhode Island driver's license numbers are seven numbers. The first two digits are the year the license was issued (i.e. 2008 is indicated by “28”). For example: 2858889.
RegEx Expression: searchctl classification add --name 'RhodeIslanddl' --regex '[1-9]{2}\d{5}'
Security:
South Carolina
Format: South Carolina driver's license numbers are a nine numbers, unformated. For example: 100179226.
RegEx Expression: searchctl classification add --name 'SouthCarolinadl' --regex '\d{9}'
Security:
South Dakota
Format: South Dakota driver's license numbers are eight numbers, unformated. For example: 10616775.
RegEx Expression: searchctl classification add --name 'SouthDakotadl' --regex '\d{8}'
Security:
Tennessee
Format: Tennessee driver's license numbers can consist of eight or nine numbers, unformated. For example: 101915638.
RegEx Expression: searchctl classification add --name 'Tennesseedl' --regex '\d{8,9}'
Security:
Texas
Format: Texas driver's license numbers are eight numbers, unformated. For example: 17600550.
RegEx Expression: searchctl classification add --name 'Texasdl' --regex '\d{8}'
Security:
Utah
Format: Utah driver's license numbers are a nine numbers, unformated. For example: 400138831.
RegEx Expression: searchctl classification add --name 'Utahdl' --regex '\d{9}'
Security:
Vermont
Format: Vermont driver's license numbers are eight numbers, unformated. For example: 17600550.
RegEx Expression: searchctl classification add --name 'Vermontdl' --regex '\d{8}'
Format: Vermont driver's license numbers can also consist of seven numbers and one letter. For example: 8205059A.
RegEx Expression: searchctl classification add --name 'Vermontdl2' --regex '\d{7}[a-zA-Z]'
Security:
Virginia
Format: Virginia driver's license numbers consist of one letter and eight numbers, unformated. For example: A20600249.
RegEx Expression: searchctl classification add --name 'Virginiadl' --regex '[a-zA-Z]\d{8}'
Format: Virginia driver's license numbers may also consist of one letter and eight numbers formatted as L##-##-####. For example: T16-70-0185.
RegEx Expression: searchctl classification add --name 'Virginiadl2' --regex '[a-zA-Z]\d{2}-\d{2}-\d{4}'
Security:
Washington
Format: All newly issued or renewed Washington state driver’s licenses will be given a new license number. New numbers will begin with “WDL” followed by a string of nine randomly assigned letters or numbers. Leters A, E, I, O U, Q and V are excluded. For example: WDLBCDF789GK
RegEx Expression: searchctl classification add --name 'Washingtondl' --regex '(WDL?)[B-DF-HJ-NPR-TW-Z]{4}\d{3}[A-Z]{2}'
Format: Untill 2024 old Washington state driver's license numbers use the format: three letters ** two letters, three numbers, one letter, and one number. For example, DOE**MJ501P1.
RegEx Expression: searchctl classification add --name 'Washingtondl2' --regex '[a-zA-Z]{3,7}\*?\*?[a-zA-Z]{1,2}\d{3}[a-zA-Z]{1,2}\d?'
Security:
Washington D.C.
Format: Washington, D.C. driver's license numbers are a seven numbers, unformated. For example: 9992616.
RegEx Expression: searchctl classification add --name 'WashingtonDCdl' --regex '\d{7}'
Security:
West Virginia
Format: Post 2020 West Virginia Real ID driver's license numbers are one letter and six numbers, unformated. For example: R899168.
RegEx Expression: searchctl classification add --name 'WestVirginadl' --regex '[a-zA-Z]\d{6}'
Format: West Virginia driver's license may also consist of seven numbers, unformated. For example, 1899168.
RegEx Expression: searchctl classification add --name 'WestVirginadl2' --regex '\d{7}'
Security:
Wisconsin
Format: Wisconsin driver's license numbers are one letter and 13 numbers formatted as L###-####-####-##. For example: J525-4209-0465-05.
RegEx Expression: searchctl classification add --name 'Wisconsindl' --regex '[a-zA-Z]\d{3}-\d{4}-\d{4}-\d{2}'
Security:
Wyoming
Format: Wyoming driver's license numbers are nine numbers formatted as ######-###. For example: 050070-003..
RegEx Expression: searchctl classification add --name 'Wyomingdl' --regex '\d{6}-\d{3}'
Security: