Eyeglass Administration guides Publication
Cloud Browser for Data Mobility
Home
- Overview
- Capabilities Overview Summary
- How Data AnyWhere Orchestration Works
- Video Overview
- Prerequisites
- AWS IAM Policy Example for User and System S3 buckets
- Golden Copy Service IAM (archivedfolders)
- End User IAM (Credentials)
- How to configure Cloud Browser for Data Mobility
- Testing end-user Cloud Browser Data Mobility
- Monitoring User job Activity
Overview
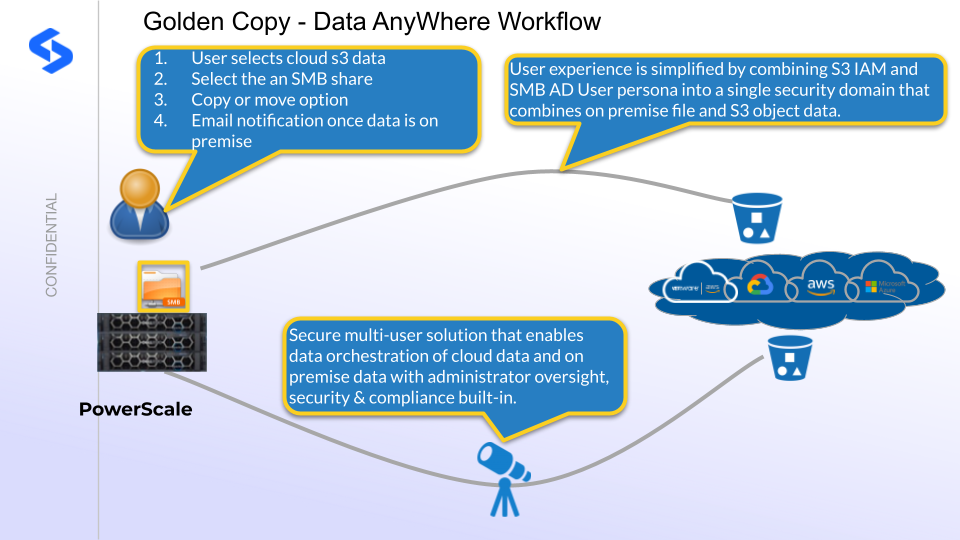
This unique capability allows customers to bring cloud object storage and on premise data storage into a secure, centrally managed , self service portal for end users to copy/move/sync cloud object data into SMB shares. This portal provides IT a centralized tool to monitor user data transfers along with each users SMB and S3 permissions enforced keeping the data secure. An audit trail of who did what when is available along with detailed file and object level reporting on what data was orchestrated between cloud and on premise storage.
- The web based user interface stores a view of S3 bucket level access dynamically detected from AWS S3 service and the SMB shares are dynamically detected based on Active Directory login.
- The user can select data from the cloud and have them moved, copied or synced to on premise storage for editing workflows.
- Golden Copy has advanced data orchestration features to allow JED (Just Enough Disk) editing workflows to cache on premise data for high speed low latency playback and editing. End of day work is moved back to the cloud automatically and data that stays on premise is backed up automatically.
- End users see an endless pool of storage in the cloud and can launch data mobility jobs without IT assistance in the self service portal. The jobs can email the user when the data movement is completed or they can monitor the job from the GUI.
- Full multi-tenant user access gives administrators the ability to monitor jobs for all users and track security of data management tasks easily from a single pane of glass showing data assets on premise or in the cloud and who did what when.
Use Cases
- Media & Entertainment - editors, content creators can select digital assets from cloud repositories to check out the data for on premise workflows, editing
- Life Sciences - Researchers can retrieve archived data generated from instruments used in on premise research and analytics workflows
- Security Professionals - Security logs, and artifacts archived by security tools can be retrieved from Cloud storage archives and presented locally on SMB file systems for analysis
Capabilities Overview Summary
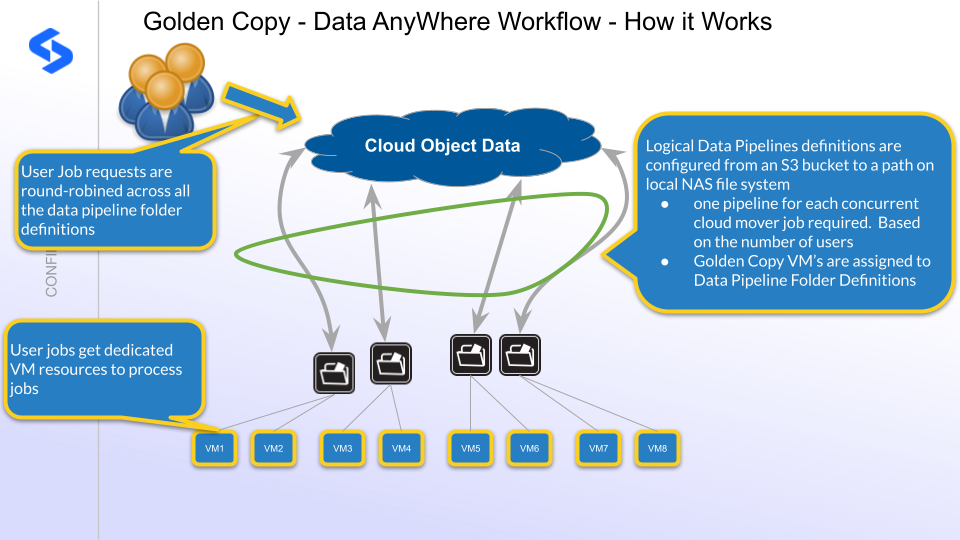
How Data AnyWhere Orchestration Works
NOTE: This requires 1.1.20 release or later for concurrent user job orchestration
Video Overview
Prerequisites
- Pipeline license subscription
- Advanced License key
- Per Seat license for each user that will use the workflow
- AWS s3 service
AWS IAM Policy Example for User and System S3 buckets
- The following examples are required minimum permissions needed
- These policies were created based on these guidelines: The absolute minimum permissions necessary for a user to use CBDM
- Ensure these permissions are scoped to the bucket wherever possible. NOTE: Not all permissions support resource scoping. Example Listbuckets is not supported by AWS IAM policies.
- Golden Copy Service account IAM:
- Added to folder definitions
- Staging Bucket: Copies objects from the User bucket to the Staging bucket. This account needs ListBucket and GetObject permission on All User Buckets. The scope can be limited to buckets with certain prefixes.
- Staging Data: This account is used to read data from the staging bucket and copy or move the data on-premise.
- Trash Bucket: This account is used to Copy data to the Trash bucket and then Delete the data from the staging bucket. The trash bucket provides a way to recovery data if necessary. It is recommended to use a lifecycle policy on the trashbukcet to delete objects every 30 days.
- End User IAM Accounts:
- Add user key Credentials to the profiles. A profile is created for users that login to Golden copy with an Active Directory user ID. This profile allows S3 credential(s) to be added.
- Used to Browser buckets.
- Used to Move job data on-premise and requires Delete permissions to objects in the source bucket.
- No permissions are needed for the Staging and Trash buckets that are managed by Golden Copy service account. This ensures staging data is secure and invisible to end users.
How to configure Cloud Browser for Data Mobility

|
The prefix for gcdm must be in the lower case as it is case-sensitive. |
- Add icon to the GUI for users that need to use Cloud Browser for Data Mobility workflows
- On Golden Copy node 1
- login ssh as ecaadmin
- nano /opt/superna/eca/eca-env-common.conf
- Add this variable
- export ENABLE_CONTENT_CREATOR=true
- Pipeline NFS mount configured for data recall on Golden Copy
- Note covered in this guide is creating the NFS mount on all Golden Copy nodes in fstab to setup the recall NFS mount and use the /ifs/fromcloud/ path on the target cluster.
- NOTE: The NFS mount path AND the --recall-sourcepath flag on the searchctl isilons modify command MUST match the NFS mount path above.
- See the Guide here.
- Set the recall data location for cloud data on the cluster
- searchctl isilons modify --name xxxx --recall-sourcepath /ifs/fromcloud (where xxxx is the cluster name added to Golden Copy)
- This path will uniquely store all data arriving from the cloud for the CBDM pipeline configuration created below. All SMB shares to expose data to end users will need to be created under this path. More information below on exact paths needed for SMB shares for different user projects.
- Configure a pipeline from the Cloud to the on premise cluster with specific parameters needed for CBDM
- Prerequisites
- Access to create 2 x S3 buckets needed as infrastructure for GCDM workflow
- Create service account keys used by Golden Copy to manage data operations in the S3 buckets that end users will be using. The keys used require the following:
- Pipeline S3 bucket permissions: full data permissions on the buckets named below
- End user data S3 bucket permissions: list bucket, getobject, deleteobject
- At least one SMB share for testing user access
- Create an SMB share using CBDM naming syntax (Mandatory)
- For this example, create an SMB share on the PowerScale on this path for a project called movie-a /ifs/fromcloud/movie-a. Assign an AD user or AD group to this SMB share to limit access to data in this share.
- Create the test share called gcdm-movie-A
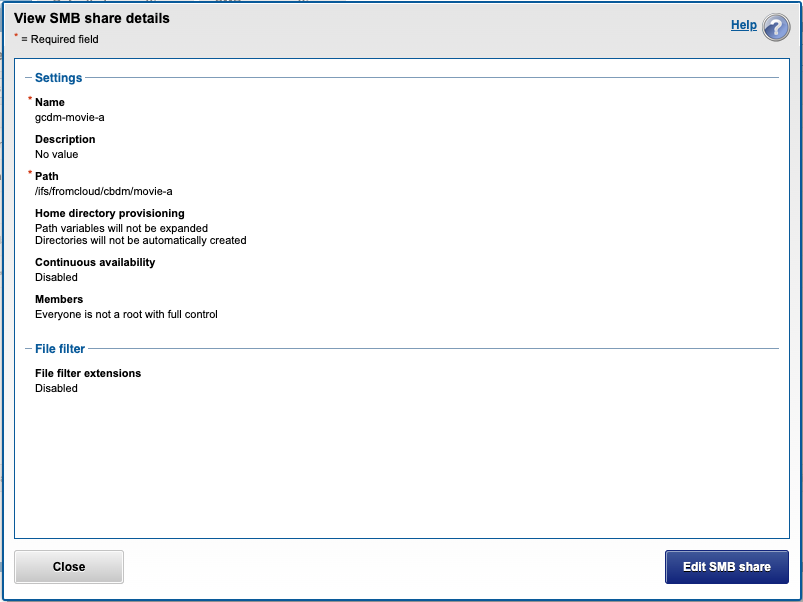
- NOTE: The SMB share names shown in the CBDM GUI will be limited to SMB shares that being with gcdm-xxxx. (where xxx is user defined share name)
- Create an SMB share using CBDM naming syntax (Mandatory)
- Configuration Example
- Create IAM user with keys to to the infrastructure buckets below
- Cloud staging bucket name - gc-cbdm-staging
- This bucket is used to stage data for on premise data orchestration, and users don't access this bucket it stores data that has been moved or copied from all user jobs.
- Cloud trash bucket name - gc-cbdm-trash
- This bucket is where all data that moves from the cloud to on premise will end up after it's copied and trashed for review by administrators.
- A life cycle policy should be set to purge this bucket after 1-5 days.
- Path for on the on premise file system on PowerScale to store all cloud data. SMB shares will be used to secure the data for each user or group of users using AD groups.
- /ifs/fromcloud - the /ifs/fromcloud is the recall nfs mount path, the /ifs/fromcloud pipeline location is where all cloud data will be stored from user jobs.
- NOTE: All smb shares will be created under this path; the data that is copied from the cloud source buckets to the file system will use this naming convention.
- NOTE: The pipeline will use the option to delete data after jobs finish from the staging bucket to keep this bucket size auto managed and clean up after jobs.
- NOTE: All SMB shares that should be visible to end users in the GUI need to have the string GCDM- in the name of the share AND fall under the pipeline path /ifs/fromcloud.
- Prerequisites
- Example pipeline CLI command using the example above
- searchctl archivedfolders add --isilon gcsource --folder /ifs/fromcloud --accesskey xxxxx --secretkey yyyyy --endpoint s3.ca-central-1.amazonaws.com --region ca-central-1 --bucket gc-cbdm-staging --cloudtype aws --source-path gcsource/pipeline --recall-from-sourcepath --recyclebucket gc-cbdm-trash --trash-after-recall.
- NOTE: This property --source-path gcsource/pipeline is a gc-cbdm-staging prefix used to ensure all data directed at the on premise cluster all gets created under a prefix in the staging bucket to avoid any data collections. We also delete all data under this prefix and is another reason this prefix is used to ensure other data is not accidently deleted. In this release the prefix is hardcoded and cannot be changed.
- searchctl archivedfolders add --isilon gcsource --folder /ifs/fromcloud --accesskey xxxxx --secretkey yyyyy --endpoint s3.ca-central-1.amazonaws.com --region ca-central-1 --bucket gc-cbdm-staging --cloudtype aws --source-path gcsource/pipeline --recall-from-sourcepath --recyclebucket gc-cbdm-trash --trash-after-recall.
- Configuration complete
Testing end-user Cloud Browser Data Mobility
- This assumes all configuration steps, SMB shares, AD accounts have already been configured.
- Login as an AD user into CBDM using Golden Copy node 1 https://x.x.x.x.
- Select profile.
- Add S3 keys and endpoint
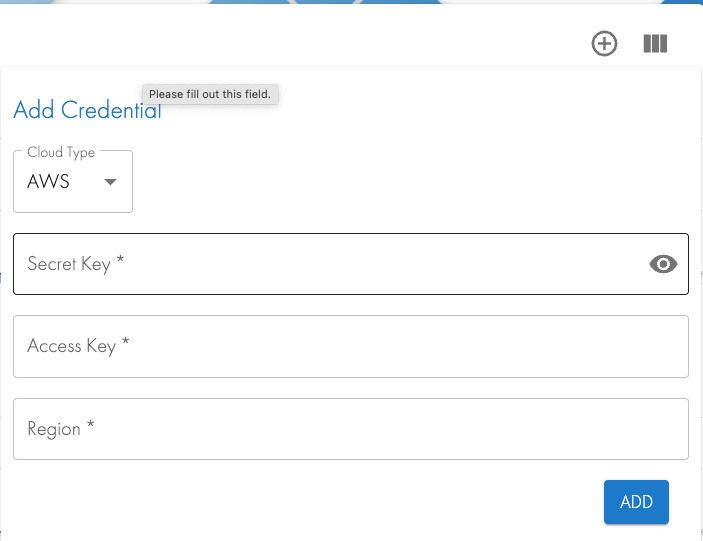
- Add an email address to be notified about job completions
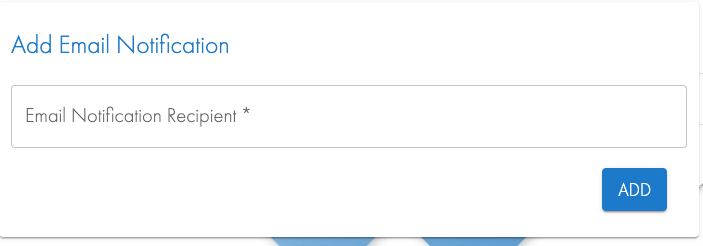
- Logout and login again.
- Open the Cloud Browser for Data Mobility workflow icon.
- Select Cloud source in Step 1. Select a bucket from the drop-down list for Step 2.
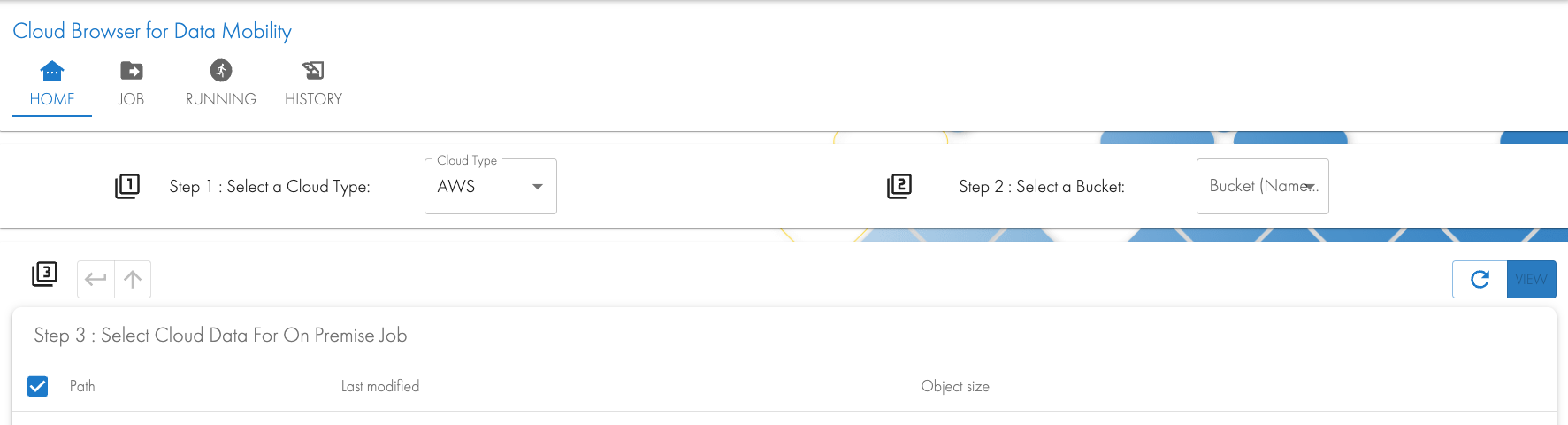
- Browse the bucket in Step 3 to select data to Copy or Move to on premise storage and click add to Job button.
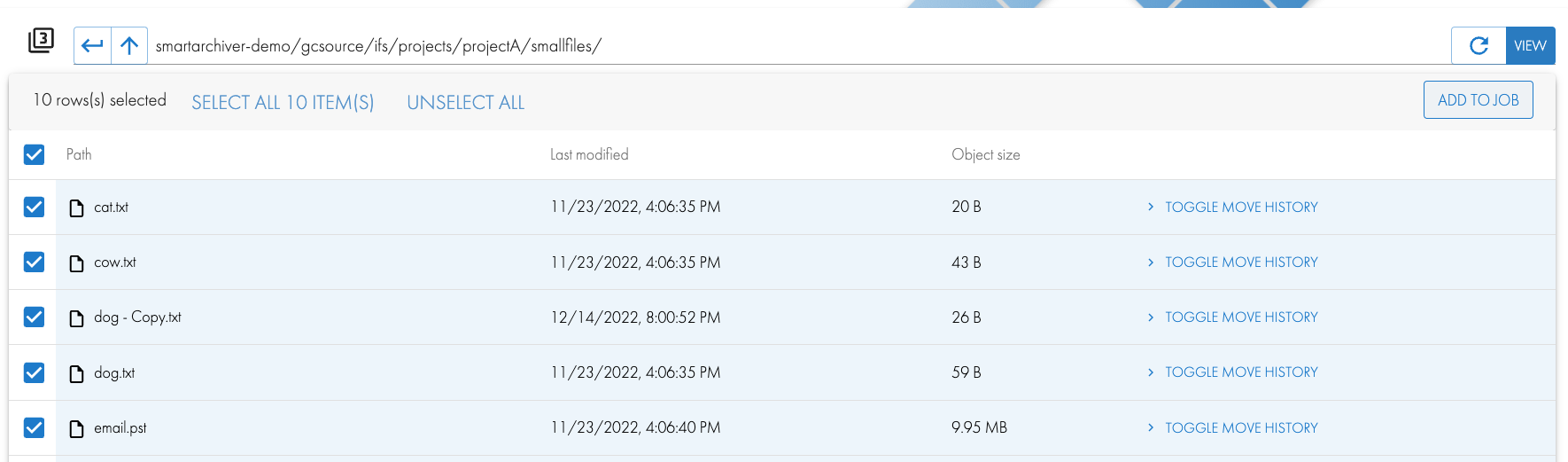
- Click the Job Icon on the top of the workflow

- Click the Run Job button and Select Cloud to On Premise Destination, Select an SMB share to copy or move the data to on the on premise storage
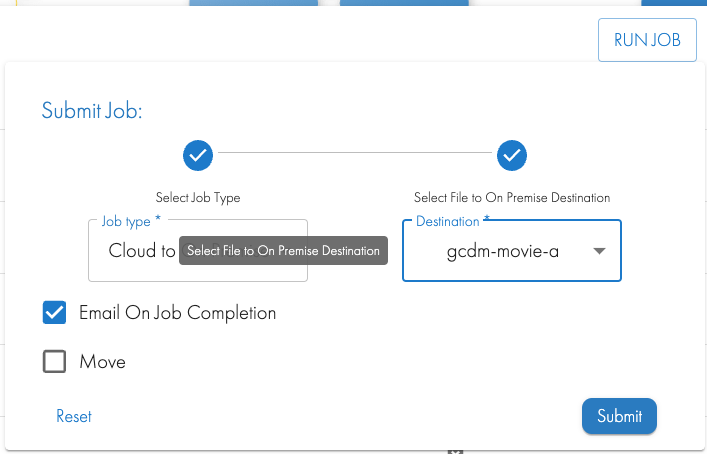
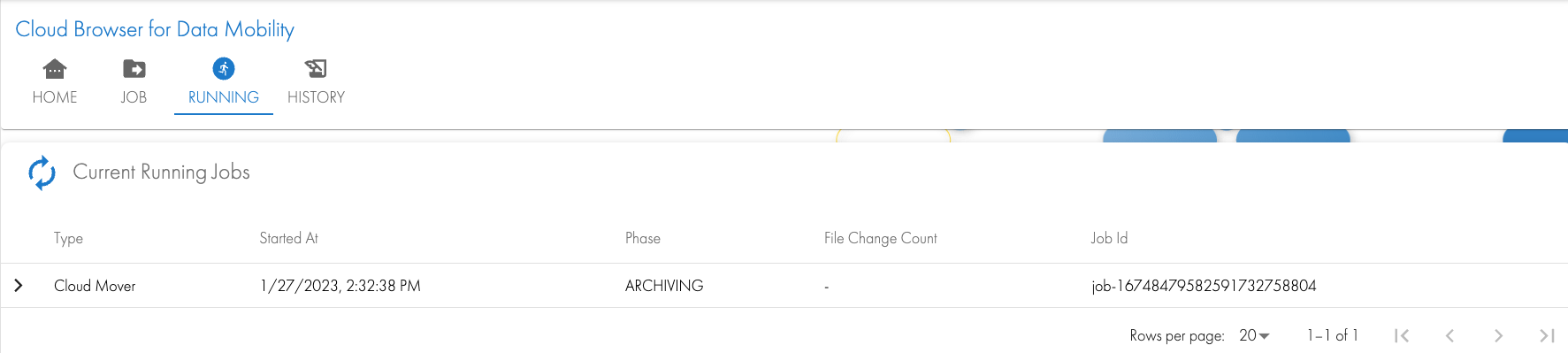
- Click Submit and wait for the GUI to show the running job. The job can be monitored
- The user will get an email with the completed copy status.
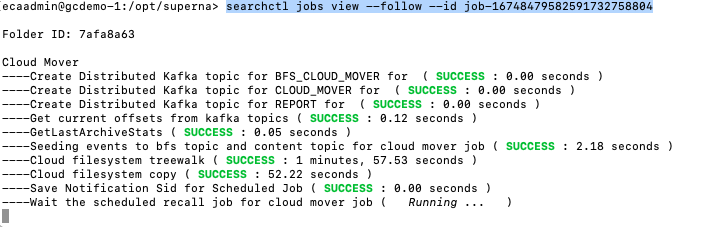
- Administrators can monitor with more detail from the CLI
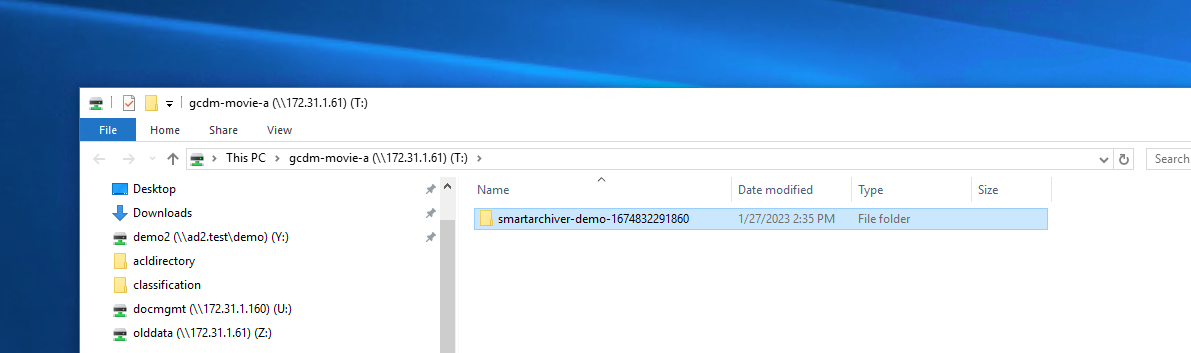
- The users mounted SMB share will show the files once they are copied or moved from the cloud.
- NOTE: The data will be copied under a folder that references the source S3 bucket.
- Email the user receives
- In the example above the source bucket was called smartarchiver-demo-xxxxx, the unique number at the end ensures data collisions do not occur on the file system)
- In side the bucket the users selected data will appear
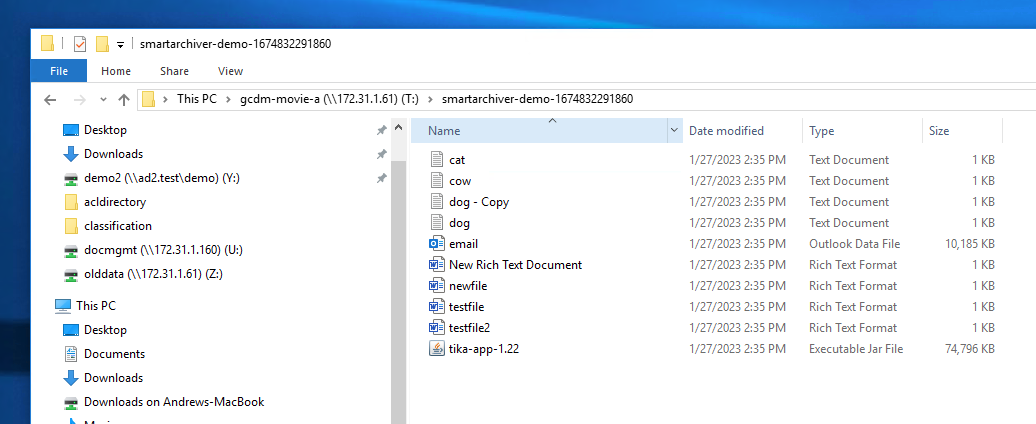
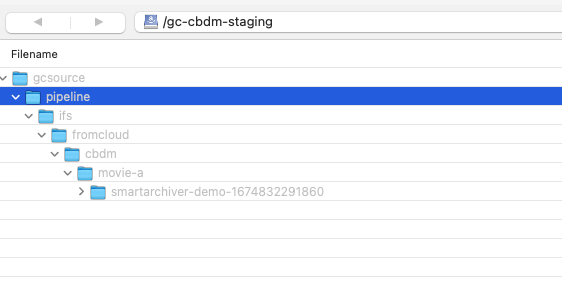
- Cloud infrastructure buckets after a Copy.
- The staging bucket has versioning enabled to show the data that was copied here temporarily and then copied to the trash can bucket before it was deleted. This allows the staging bucket to remain empty unless data is in transit to on premise storage.
- The trash bucket contains the jobs files
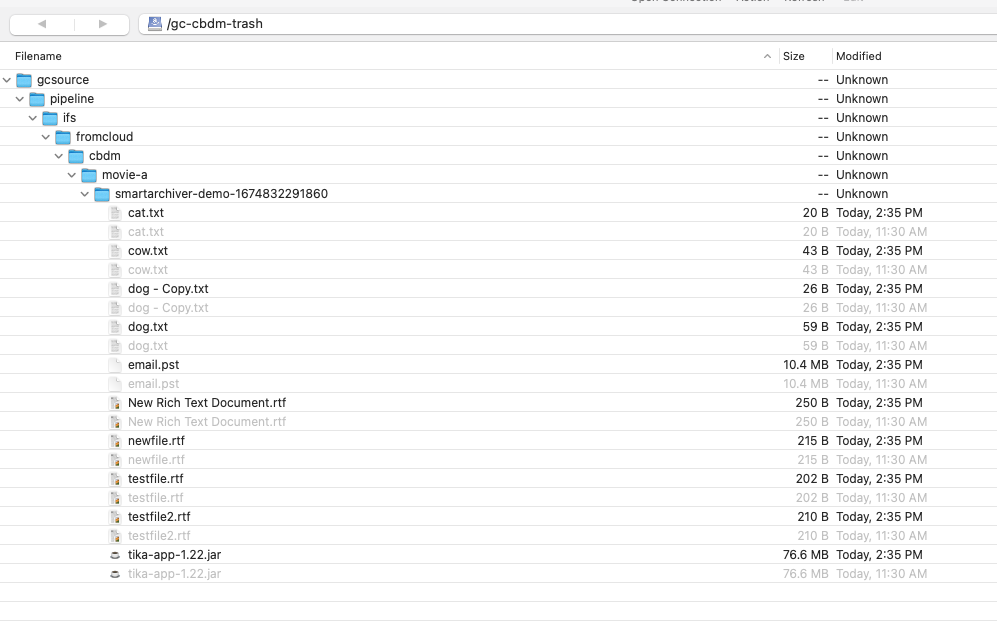
- Done.


Monitoring User job Activity
- Golden copy administrators can monitor all user jobs in the cluster by using the history tab of the Cloud Browser for Data Mobility workflow icon.
.png)