Operations Guides
Appliance Operational Procedures
Home
- Overview
- Eyeglass Common Procedures
- Shutting down the appliance
- Reboot the appliance
- IP address change
- vmotion to new ESX host
- Password Change
- ECA cluster Common Operations (Ransomware Defender, Easy Auditor, Performance Auditor, Search & Recover and Golden Copy)
- Health Monitor - Audit Data Ingestion and Audit Data Save to Database
- Restart the cluster
- Reboot a single node
- ECA cluster ip address change
- ECA password change
- ECA cluster shutdown
- Power Loss to VM or Recovery from a Reboot without graceful shutdown
Overview
This guide covers common operational questions and procedures for Eyeglass and ECA clusters.
Eyeglass Common Procedures
Shutting down the appliance
- Login as admin using ssh
- sudo -s (enter admin password)
- systemctl stop sca
- shutdown
Reboot the appliance
- NOTE: This should not be used as a trouble shooting step. This is not required for any operational steps. If a reboot is required for an operating system patch follow these steps. For all other cases open a case with support and do not reboot the appliance unless directed by support
- login as admin
- sudo -s (enter admin password)
- systemctl stop sca
- reboot
IP address change
- login as admin
- sudo -s (enter admin password)
- yast
- use arrow keys to select networking and edit interface ip settings, including, DNS and default gateway
vmotion to new ESX host
- Eyeglass can be moved between hosts without shutdown
PowerScale code upgrade see guide
Password Change
- Login as the admin user over ssh (also applies to other builtin user accounts for other products, rwdefend, auditor)
- type the command below:
passwd
- Enter new password, retype new password
- done
ECA cluster Common Operations (Ransomware Defender, Easy Auditor, Performance Auditor, Search & Recover and Golden Copy)
All of the above products share common operating procedures.
- For additional scenarios on ECA based product admin guide see the guide.
Health Monitor - Audit Data Ingestion and Audit Data Save to Database
- NOTE: These graphs should be checked every time you have errors or issues with Ransomware Defender, Easy Auditor or Performance Auditor. Each product depends on audit data ingestion. The graph should never be a flat line for received or sent audit records.
- NOTE: The actual values are only intended to show general ingestion rates and are not intended for any other purpose. The graphs can be used to monitor if ingestion is balanced across each ECA VM's. The graphs and relative rates of ingestion are for sizing the number ECA nodes 6, 9 or more following documented sizing guide lines and to monitor ingestion rates across times of day.
- The most common cause is network issues between the ECA VM' s and the cluster.
- Login to Eyeglass GUI (Requires 2.5.8 or later)
- Click the Managed Services Icon
- Click the ECA monitor button. This will launch a new browser tab to display received audit data per ECA node rate of events per minute per node and sent audit data per ECA node to the Isilon / Powerscale HDFS database.
- NOTE: The graphs should never be flat lines at the 0 events per second graph for any extended period of time. The graph shows events per minute per ECA node. 0 events per seconds is not a normal state and some positive number of events should be constantly seen.
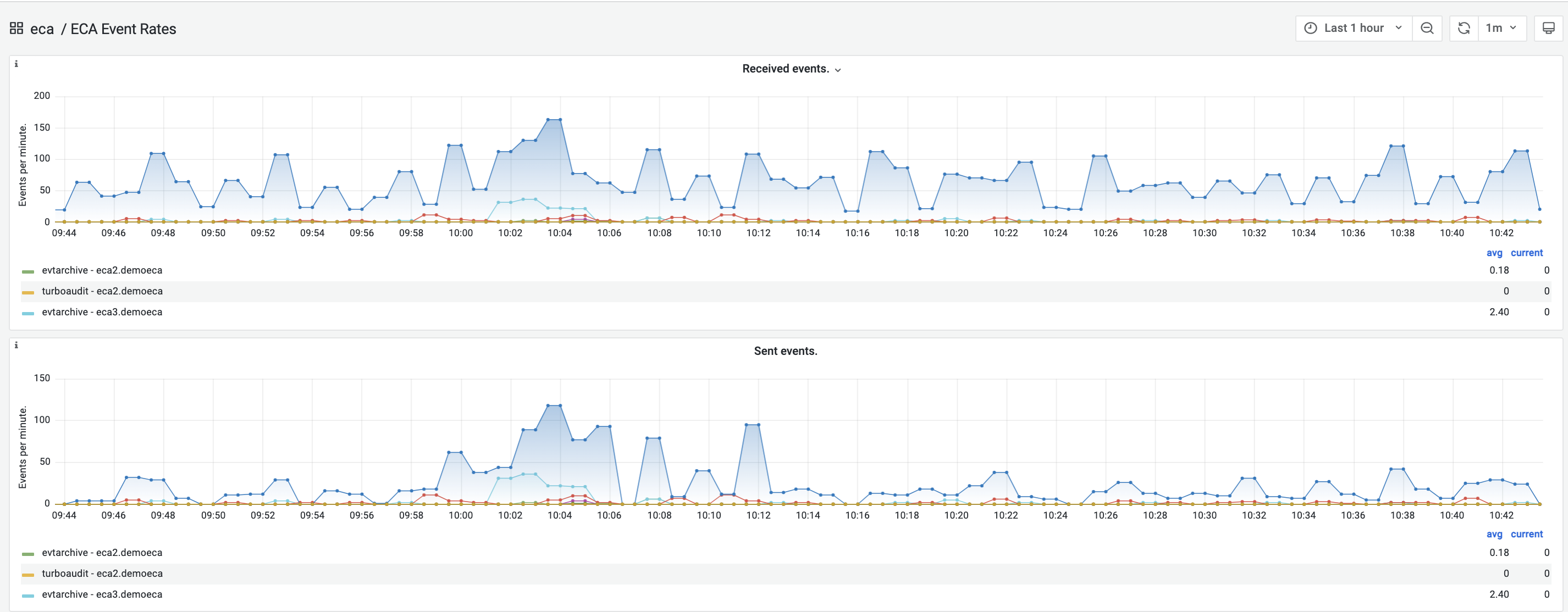
- Turbo Audit received is audit data ingestion
- evtarchive sent is audit data saving to HDFS (Easy Auditor Only)
Restart the cluster
- login to node 1 as ecaadmin over ssh
- ecactl cluster down
- then
- ecactl cluster up
- NOTE: can take 5-7 minutes to startup and shutdown all nodes in the cluster
Reboot a single node
- login to the node over ssh as ecaadmin
- sudo -s (enter admin password)
- reboot
- Now login to node 1 as ecaadmin
- ecactl cluster up (this will ensure all services are started on all nodes, even if the cluster is already running)
ECA cluster ip address change
- Review the eca admin guide
ECA password change
- Login as the ecaadmin user over ssh
- type the command below:
- passwd
- Enter new password, retype new password
- done
ECA cluster shutdown
- Use this procedure to stop the cluster software
- login to eca node 1 as ecaadmin
- type
- ecactl cluster down
Power Loss to VM or Recovery from a Reboot without graceful shutdown
- login to node 1 as ecaadmin over ssh
- ecactl cluster down
- then
- ecactl cluster up