Eyeglass Administration guides Publication
ECA Cluster Operational Procedures
Home
- Eyeglass Cluster Maintenance Operations
- Cluster OS shutdown or restart
- Cluster Startup
- ECA Cluster Node IP address Change
- Change ECA Management tool Authentication password
- Single ECA Node Restart or Host crash Affect 1 or more ECA nodes
- Eyeglass ECA Cluster Monitoring Operations
- Checking ECA database Status:
- Check overall Cluster Status
- Check Container stats memory, cpu on an ECA node
- Security
- Self Signed Certificate Replace for ECA cluster Nginx proxy
Eyeglass Cluster Maintenance Operations
Note: Restart of the OS will not auto start up the cluster post boot. Follow steps in this section for cluster OS shutdown, restart and boot process.
Cluster OS shutdown or restart
- To correctly shutdown the cluster
- Login as ecaadmin via ssh on the master node (Node 1)
- ecactl cluster down (wait until all nodes are down)
- Now shutdown the OS nodes from ssh login to each node
- ssh to each node
- Type sudo -s (enter admin password)
- Type shutdown
Cluster Startup
- ssh to the master node (node 1)
- Login as ecaadmin user
- ecactl cluster up
- Verify boot messages shows user tables exist and signal table exists (this step verifies connection to analytics database over HDFS on startup)
- Verify cluster is up
- ecactl cluster status (verify containers and table exist in the output)
- Done.
ECA Cluster Node IP address Change
To correctly change the cluster node ip addresses:
- Login as ecaadmin via ssh on the master node (Node 1)
- ecactl cluster down (wait until completely down)
- Sudo to root
- sudo -s (enter admin password)
- Type yast
- Navigate to networking to change the IP address on the interface)
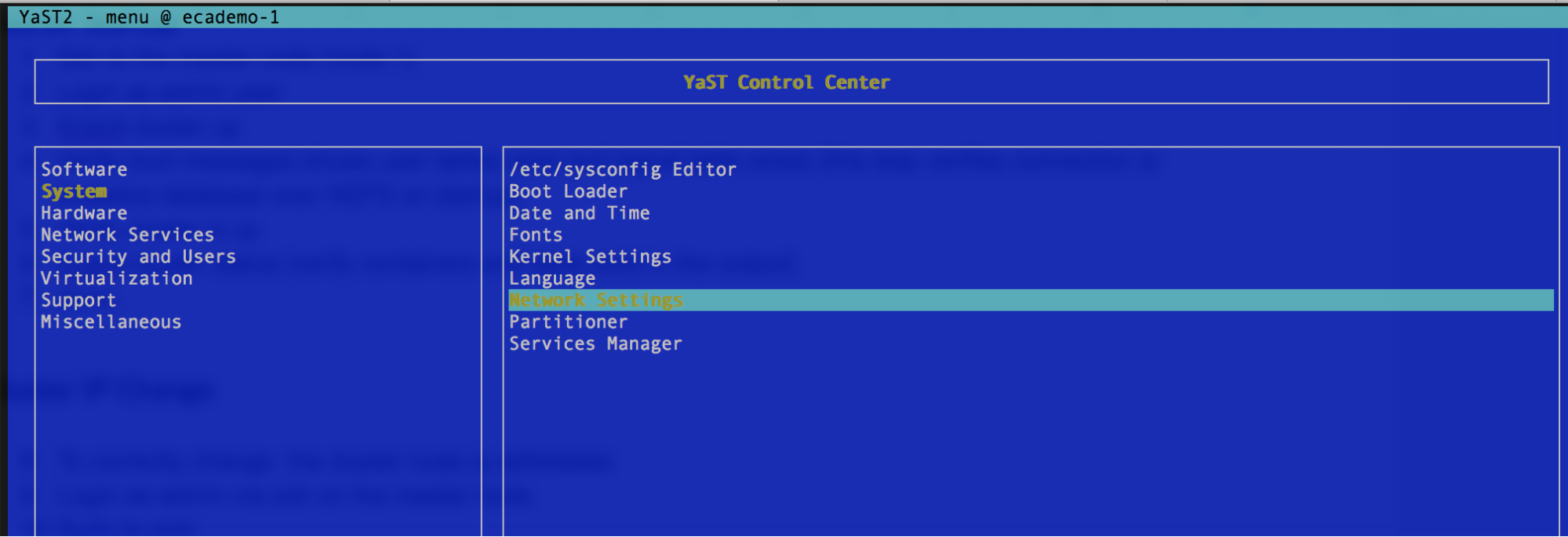
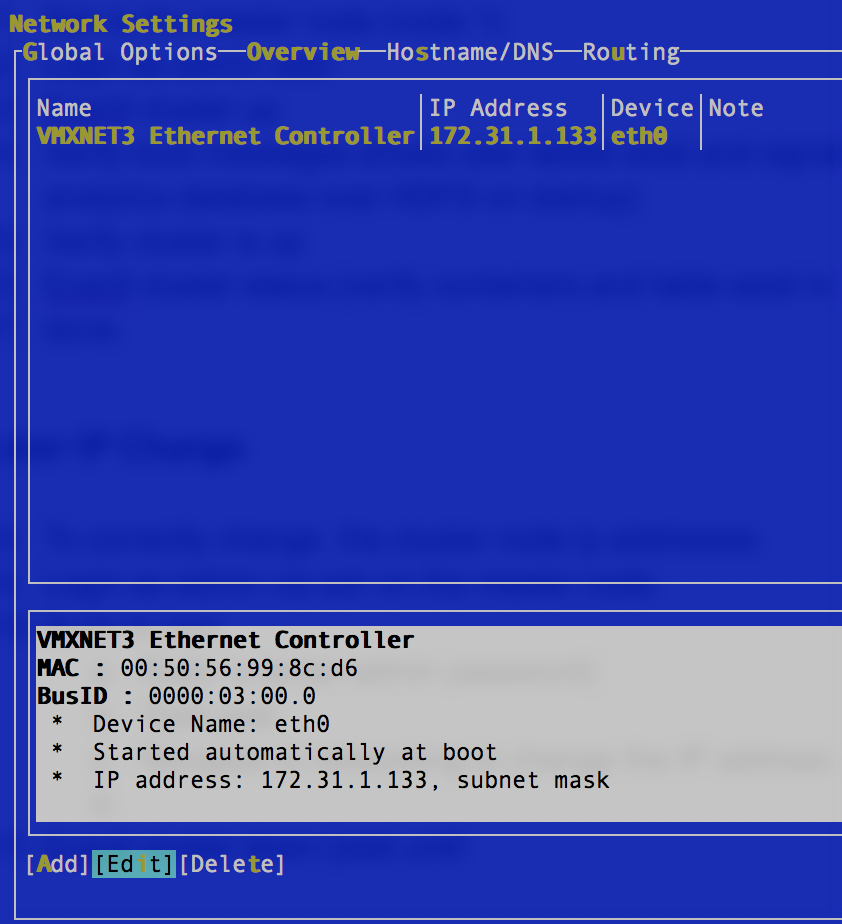
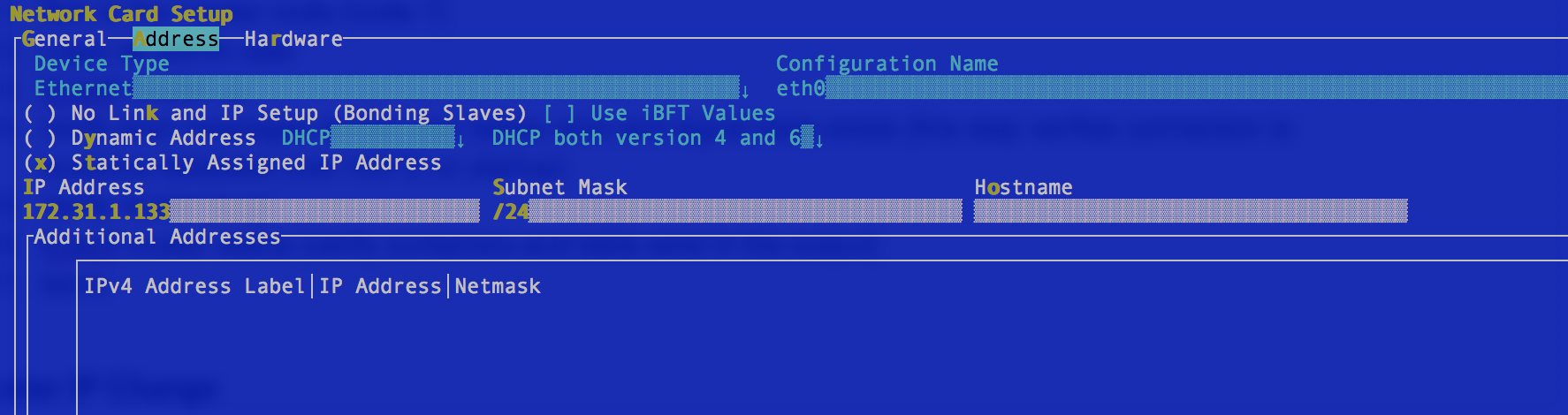
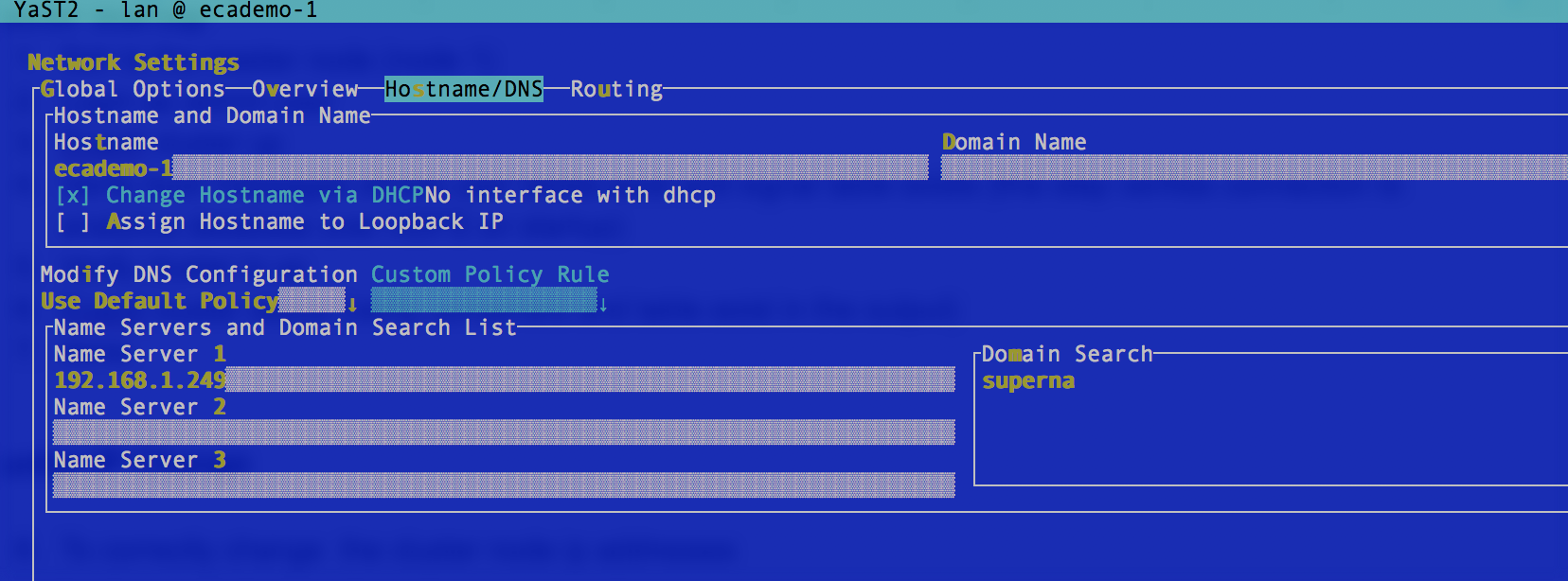
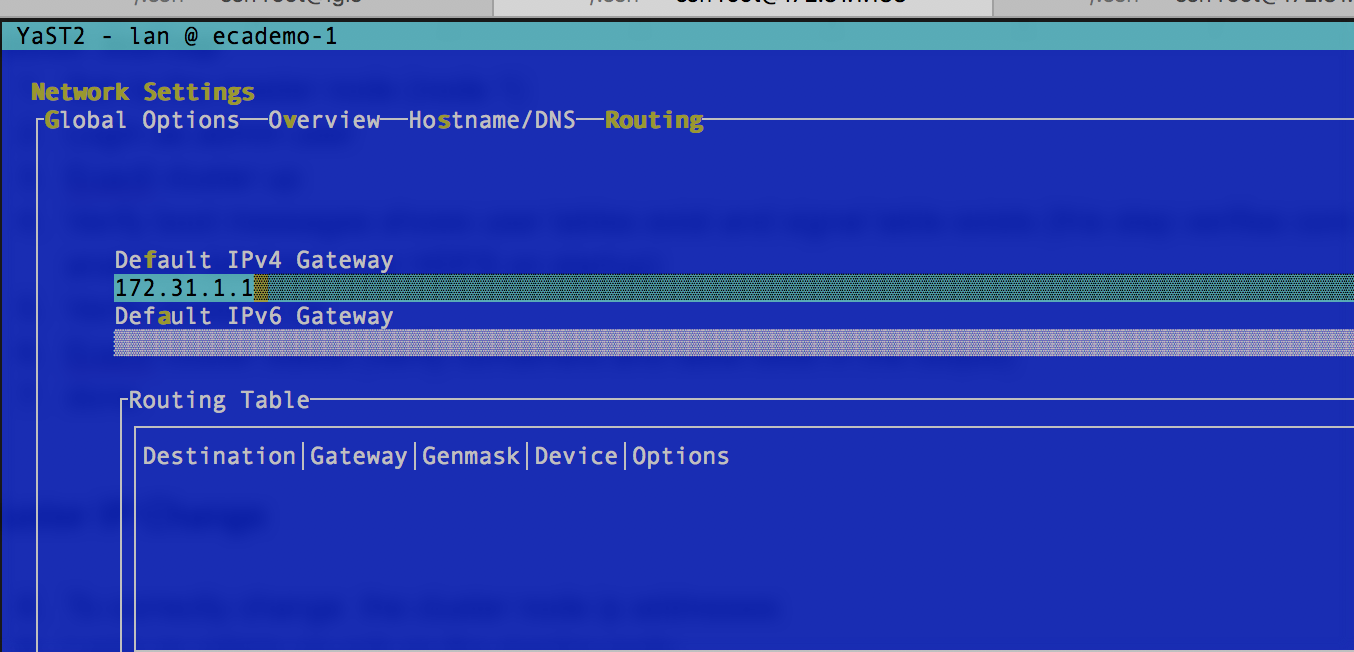
- Each screenshot shows ip, dns, router settings
- Save and exit yast
- Repeat on all nodes in the cluster
- Once completed changes verify network connectivity with ping and DNS nslookup
- Edit with ‘ nano /opt/superna/eca/eca-env-common.conf ’ on the master node (Node 1)
- Edit the ip addresses of each node to match new new settings
- export ECA_LOCATION_NODE_1=x.x.x.x
- export ECA_LOCATION_NODE_2=x.x.x.x2
- export ECA_LOCATION_NODE_3=x.x.x.x3
- Control X to exit and save
- Modify the Isilon NFS mount permissions on all clusters managed by the ECA instance. Replace the IP's to include all ECA node ip addresses. Example below shows 3 IP, check your cluster node count to update the command below to match your deployment.
- isi nfs exports modify --id 3 -f --add-root-clients="x.x.x.x, y.y.y.y, z.z.z.z"-- add-clients="x.x.x.x,y.y.y.y,z.z.z.z"
- Update the HDFS access zone with new IP addresses of the ECA VM's
- isi hdfs rack list --zone=eyeglassisi hdfs rack modify igls-hdfsrack0 --zone=eyeglass --client-ip-ranges="x.x.x.x, y.y.y.y, z.z.z.z"
- Start cluster up. Run command: ecactl cluster exec sudo rm - rf /opt/superna/mnt/zk-ramdisk/*\&\& sudo systemctl restart docker
- From master node (Node 1)
- ecactl cluster up (verify boot messages look as expected)
- Eyeglass /etc/hosts file validation
- Once the ECA cluster is up
- Login to Eyeglass as admin via ssh
- Type cat /etc/hosts
- Verify the new ip address assigned to the ECA cluster is present in the hosts file.
- If it is not correct edit the hosts file and correct the IP addresses for each node.
- Login to Eyeglass and open the Manage Services window. Verify active ECA nodes are detected as Active and Green.
- You should see the old ip addresses and inactive ECA nodes with the old ip addresses , click the red X next to each to delete these entries from the managed services icon.
- Done
Change ECA Management tool Authentication password
- Release 2.5.7 and later now protects all management tools on the ECA cluster with a user name and password over a HTTPS login page. This includes hbase, kafka, spark UI's that are accessible from the Managed Services icon in the Eyeglass GUI.
- The login to this UI is ecaadmin and default password is 3y3gl4ss
- Login to node 1 over ssh as ecaadmin user and run the command below
- NOTE: Replace <password> with the password
- ecactl cluster exec "htpasswd -b /opt/superna/eca/conf/nginx/.htpasswd ecaadmin <password>"
- done. The new password is active immediately on all nodes.
Single ECA Node Restart or Host crash Affect 1 or more ECA nodes
Use this procedure when restarting one ECA node, which under normal conditions should not be done unless directed by support. The other use case is when a host running an ECA VM is restarted for maintenance and a node will leave the cluster and needs to rejoin.
- On the master node
- Login via ssh as ecaadmin
- Type command : ecactl cluster refresh (this command will re-integrate this node back into the cluster and check access to database tables on all nodes)
- Verify output
- Now type: ecactl db shell
- type : status
- Verify no dead servers are listed
- If no dead servers
- Login to Eyeglass GUI, check Managed Services and verify all nodes are green.
- Cluster node integration procedure completed.
Eyeglass ECA Cluster Monitoring Operations
Checking ECA database Status:
- ecactl db shell [enter]
- status [enter]
Check overall Cluster Status
- ecactl cluster status
Check Container stats memory, cpu on an ECA node
- ecactl stats (auto refreshes)
Security
Self Signed Certificate Replace for ECA cluster Nginx proxy
- SSH to ECA node 1
- Run command: cd /opt/superna/eca/conf/nginx
- Run command: mv nginx.crt nginx.crt.bak
- Run command: mv nginx.key nginx.key.bak
- Run command (replace the yellow domain name and the IP in the command):
- openssl req -new -x509 -sha256 -newkey rsa:2048 -nodes -keyout nginx.key -days 365 -out nginx.crt -subj "/CN=st-search-1.ad2.test" -addext "subjectAltName=DNS:st-search-1.ad2.test,IP:172.25.24.224"
- Run command: ecactl cluster push-config
- Run command: ecactl cluster services restart --container nginx --all