Eyeglass Administration guides Publication
Cloud Pool Reporting
Home
© Superna Inc
- Overview
- Use Cases
- Examples of how to Search for File Stubs
- How to report on GB's of Cloudpool stubs that are being accessed
Overview
Search & Recover is the only product that fully supports Cloudpool reporting. This desribes how Cloudpool status can be used in the Search UI and Quick reports.
Use Cases
- Index cloud pool data to track which files are stubs and which are not to make sure File Pool policies are correctly matching the expected files.
- Quick report to show the total sum of all stub files including total count of files, and total GB of stub files currently in the cloud tier.
- Advanced search ability to search file files using any supported criteria.
Examples of how to Search for File Stubs
- Advanced Search UI Option allows searching for Stub files only.
- Quick Report Who Owns What?, What are the Types?, What's growing old? all have an advanced search option to select Cloudpool Status Archived when searching to narrow the results to only include stub files.

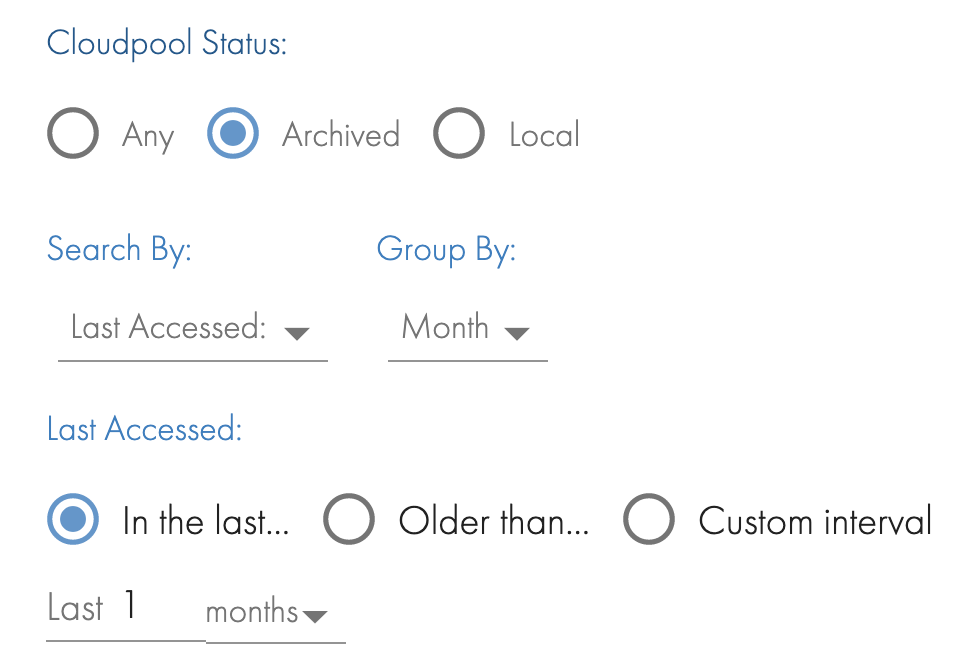
How to report on GB's of Cloudpool stubs that are being accessed
- If Cloudpool stubs are being accessed frequently, it indicates the files are not good candidates to be tiered to slower S3 tier. These steps will identify Cloudpool files that are still being accessed and will allow reporting on the files along with the owner of the files.
- Open the Quick reports Tab and configure the What's Growing Old? Quick report.
- Select the Cloudpool status Archived
- Select the Last Accessed option in the last 1 month
- The results will show the quantity of data in the last 30 days that has been accessed (requires the last accessed attribute to be enabled on the cluster).
- The table below will show the quantity of data and selecting this with the check box and Action menu Show my the files will allow reporting on the files that are being accessed.
- This list would be reviewed to see which users are accessing data and where in the the file system the files exist. This review can be used to revise the File Pool policy that is stubbing files.