Bulk Ingest old Audit Data from PowerScale to Easy Auditor
- Overview
- Limitations
- Bulk Ingestion GUI
- Requirements and limitations
- How to Bulk Ingest with Easy Auditor GUI
- PowerScale Steps for Manual Audit data ingestion CLI < 2.5.11 releases
- Eyeglass steps
- How to View Progress of Bulk Audit Data Ingestion
- Start up Queue Monitor Process
- View Ingestion Jobs
- View Event Ingestion progress
Overview
Use these instructions to re-ingest audit data from PowerScale's audit directory into Easy Auditor's index.
Limitations
- Not supported for ingesting days, weeks months or years of data. Only supported for targeted specific date of an event. Support will not assist in bulk ingestion. Support of any use case other than targeted day is not supported under the support contract.
- No possible method to predict time to ingest audit data.
- IMPORTANT: Maximum number of files that can be added to json file to be run at any time = 20. ANY HIGHER NUMBER IS NOT SUPPORTED. Initial testing should be done with only 1 file. Use cron to run at non-busy time.
- NOTE: Submitting more than one json file will queue the jobs and only 1 ingestion job will execute at a time.
- NOTE: bulk ingestion is a background task and processing of current audit data has higher priority. There is no way to change this priority and no way to predict completion times since active audit data will take priority.
Bulk Ingestion GUI
Requirements and limitations
- Release 2.5.9 or later
- 1 concurrent running job
- queue of additional jobs
- only 3 days to select files to submit in a job.
How to Bulk Ingest with Easy Auditor GUI
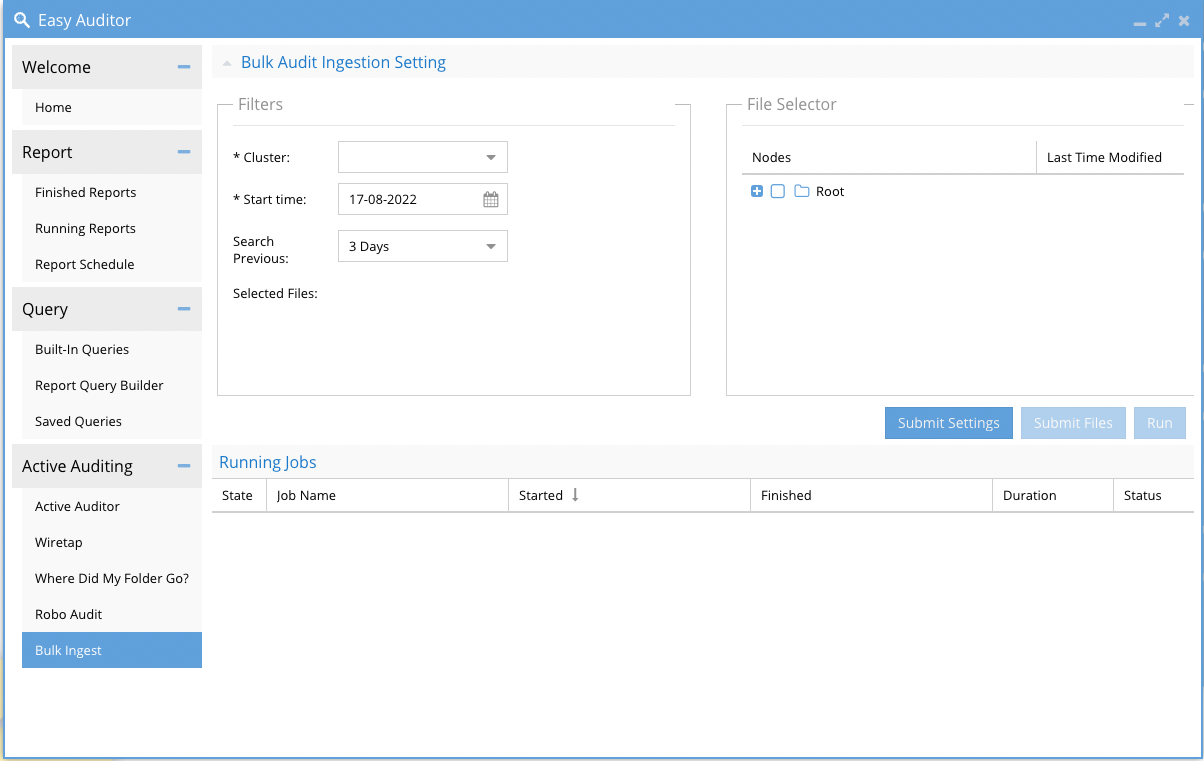
- For bulk ingestion, one should follow these steps:
Before using this feature follow these steps:
a. Make a directory in ECA clusters /opt/superna/mnt/bulkingestion/<cluster-guid>/<cluster-name> if it’s not existed.
b. Use the CLI command to setup the non-default path: igls config settings set --tag=bulkingestpath --value= PATH (gz files should be saved in this PATH in isilon)
Note: All files should be in the protocol folder in each node, for example /PATH/node-name/protocol
c. Create an NFS Export in the above path and add the ECA nodes IPs in the client IP.
d. Edit /opt/superna/eca/data/audit-nfs/auto.nfs on each ECA node by adding /opt/superna/mnt/bulkingestion/<cluster-guid>/<cluster-name> --fstype=nfs,nfsvers=4,ro,soft <FQDN>:<PATH>. (gz files should be saved in this PATH in isilon)
e. Mount export on each ECA node using: sudo /opt/superna/eca/scripts/manual-mount.shor run cluster down/up.
6. Click the Submit Files button to add the files to the job definition.
7. Start the job with the Run Job button.
8. Monitor the running job in the lower part of the GUI until it completes.
9. You can select more files without waiting for the job to finish by configuring a new job and file selection and submit the job to run. Only a single job will run concurrently due to resources reserved for ingestion. The job will queue until the previous job completes.
10. Done.

|
IMPORTANT: Make sure that this line If there isn’t such a line in docker-compose.yml, please add it and run |
PowerScale Steps for Manual Audit data ingestion CLI < 2.5.11 releases
- SSH to the PowerScale cluster you intend to re-ingest audit logs from
Navigate to the directory you intend to re-ingest audit logs from. This directory is at the bottom of the below path (choose node8 as it was the most recent but yours will vary):
cd /ifs/.ifsvar/audit/logs/node008/protocol List the contents. This will assist determining which audit data based on dates/times to re-ingest. The audit logs are listed as .gz files.
ls -lT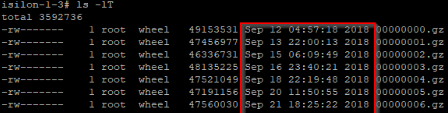
Each cluster node will have GZ files on the date you ingesting from. All cluster nodes will need to have the GZ files ingested. Repeat the steps above for each cluster node folder and locate the GZ files on the date and make a note of the file names for each node.
Build the file below for ingestion and submit gz files in groups of 20 files at a time. Multiple gz files can be queued for ingestion but only 1 will ingest at a time
Eyeglass steps
- SSH to Eyeglass CLI as
admin - Navigate to
cd /opt/superna/sca/data/bulkingest - Create a file
touch bulkingest.json - Open the file in vim editor
vim bulkingest.json - Copy paste content below (if ingesting from a single node), substituting in the following for your own:
[{
"cluster_name": "YOUR_PowerScale_CLUSTER_NAME",
"cluster_guid": "YOUR_PowerScale_CLUSTER_GUID",
"node": [{
"node_id": "node008",
"audit_files": ["node_audit_file.gz", "node_audit_file.gz"]
}
]
}] - Save the file
:wq! If you wish to ingest from multiple nodes, please use the below code
EXAMPLE:
[{
"cluster_name": "YOUR_PowerScale_CLUSTER_NAME",
"cluster_guid": "YOUR_PowerScale_CLUSTER_GUID",
"node": [{
"node_id": "node008",
"audit_files": ["node_audit_file.gz", "node_audit_file.gz"]
},
{
"node_id": "node003",
"audit_files": ["node_audit_file.gz", "node_audit_file.gz", "node_audit_file.gz", "node_audit_file.gz"]
}
]
}]- Save the file
:wq! - Execute the bulkingest.json file (must be absolute path, does not matter where the file is located):
igls rswsignals bulkLoadTAEvents --file=/opt/superna/sca/data/bulkingest/bulkingest.json
NOTE: Depending on how large a period of time is being ingested, it can take some time to complete.
How to View Progress of Bulk Audit Data Ingestion
- NOTE: Each Isilon node has historical audit data and each file is 1GB in size compressed, each node may have multiple files to ingest for a given day. The higher the audit rate the more GZ files that will need to be ingested. This can be a slow process for multiple days of historical audit data.
Start up Queue Monitor Process
- Login to node 1 of the ECA cluster and run this command
- ecactl containers up -d kafkahq
View Ingestion Jobs
- Open the Eyeglass Jobs Icon running jobs tab to view the bulk ingestion task to verify it is running, each CLI command will start an audit job to process the files in the json configuration file
- RUNNING Jobs Screen
- You need to wait for this to finish before submitting more files. Currently processing
- Wait for Spark Job step must show a blue checkmark to indicate it is finished processing this job.
- Spinning symbol means it is in progress.
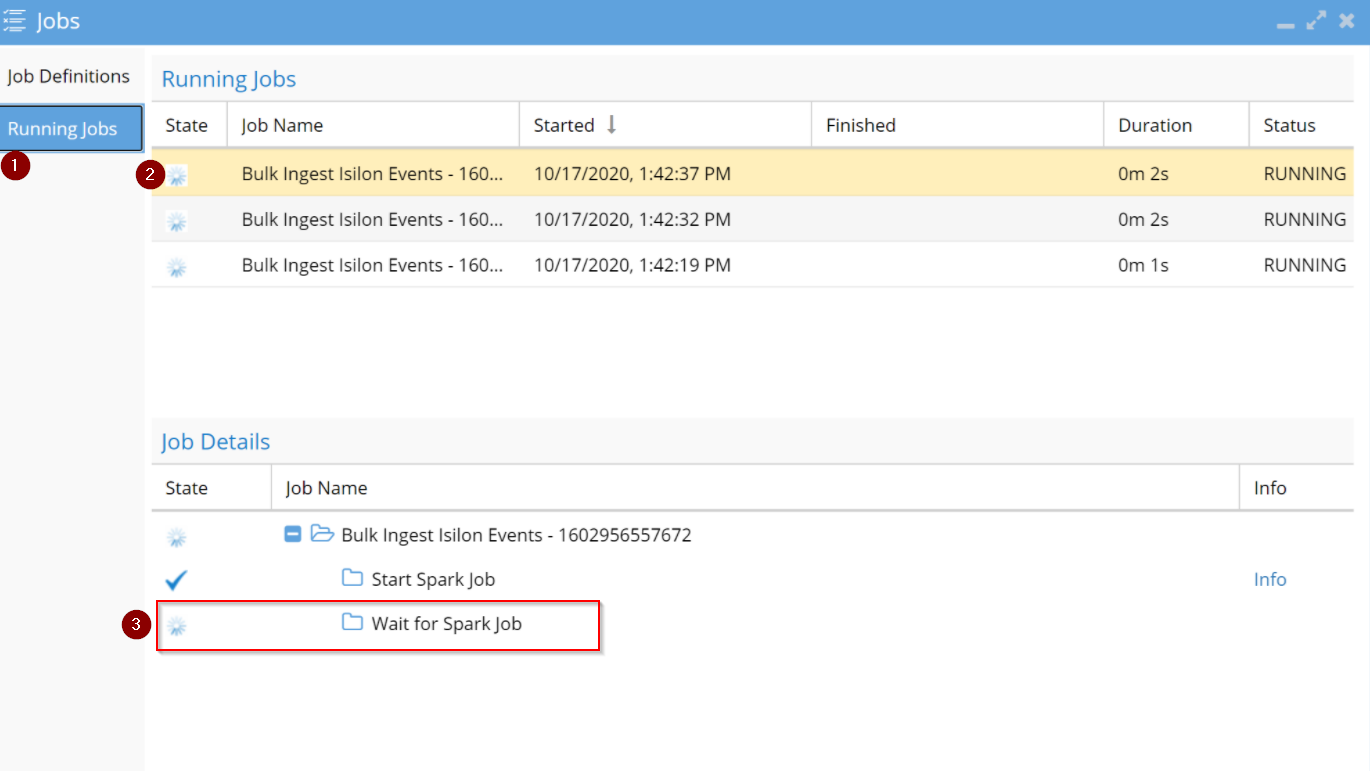
- Open the Eyeglass Jobs Icon running jobs tab to view the bulk ingestion task to verify it is running, each CLI command will start an audit job to process the files in the json configuration file
View Event Ingestion progress
- Using a browser http://x.x.x.x/kafkahq ( x.x.x.x is node 1 of the ECA cluster IP address) login with th ecaadmin user and default password 3y3gl4ss
- Topics - in our case we are tracking specific bulkingestion topic
- Bulkingestion - The topic used to track current progress on ingestion task
- Lag - this can go UP/Down depending on the ingestion speed. A value of 0 means the ingestion job is finished and no more files events are being processed for the current active job. Check running Jobs icon to verify the active job shows finished. Any queued Jobs will start automatically.
- Count - this field should always show an increase as new events are processed from all jobs. Once you add more json files to the queue this value will increase as events are ingested. This field will always increase each time ingestion jobs are run.
